
Understanding Deep Face Representation via Attribute Recovery
Deep neural networks have proven to be highly effective in the face recognition task, as they can map raw samples into a discriminative high-dimensional representation space. However, understanding this complex space proves to be challenging for human observers. In this paper, we propose a novel approach that interprets deep face recognition models via facial attributes. To achieve this, we introduce a two-stage framework that recovers attributes from the deep face representations. This framework allows us to quantitatively measure the significance of facial attributes in relation to the recognition model. Moreover, this framework enables us to generate sample-specific explanations through counterfactual methodology. These explanations are not only understandable but also quantitative. Through the proposed approach, we are able to acquire a deeper understanding of how the recognition model conceptualizes the notion of identity and understand the reasons behind the error decisions made by the deep models. By utilizing attributes as an interpretable interface, the proposed method marks a paradigm shift in our comprehension of deep face recognition models. It allows a complex model, obtained through gradient backpropagation, to effectively communicate with humans. The source code is available here, or you can visit this website: https://github.com/RenMin1991/Facial-Attribute-Recovery.
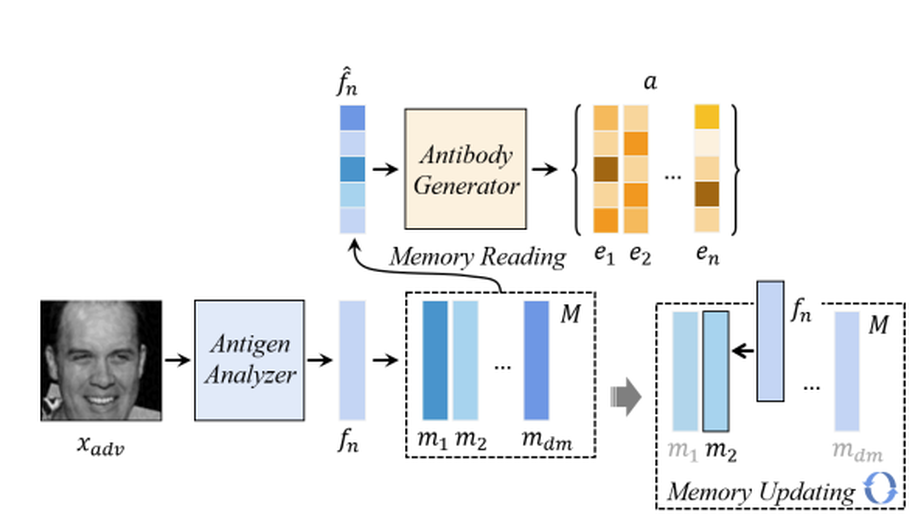
Artificial Immune System of Secure Face Recognition Against Adversarial Attacks
Deep learning-based face recognition models are vulnerable to adversarial attacks.In contrast to general noises, the presence of imperceptible adversarial noises can lead to catastrophic errors in deep face recognition models. The primary difference between adversarial noise and general noise lies in its specificity. Adversarial attack methods give rise to noises tailored to the characteristics of the individual image and recognition model at hand. Diverse samples and recognition models can engender specific adversarial noise patterns, which pose significant challenges for adversarial defense. Addressing this challenge in the realm of face recognition presents a more formidable endeavor due to the inherent nature of face recognition as an open set task. In order to tackle this challenge, it is imperative to employ customized processing for each individual input sample. Drawing inspiration from the biological immune system, which can identify and respond to various threats, this paper aims to create an artificial immune system (AIS) to provide adversarial defense for face recognition. The proposed defense model incorporates the principles of antibody cloning, mutation, selection, and memory mechanisms to generate a distinct “antibody” for each input sample, where in the term “antibody” refers to a specialized noise removal manner. Furthermore,we introduce a self-supervised adversarial training mechanism that serves as a simulated rehearsal of immune system invasions. Extensive experimental results demonstrate the efficacy of the proposed method, surpassing state-of-the-art adversarial defense methods. The source code is available here, or you can visit this website: https://github.com/RenMin1991/SIDE.
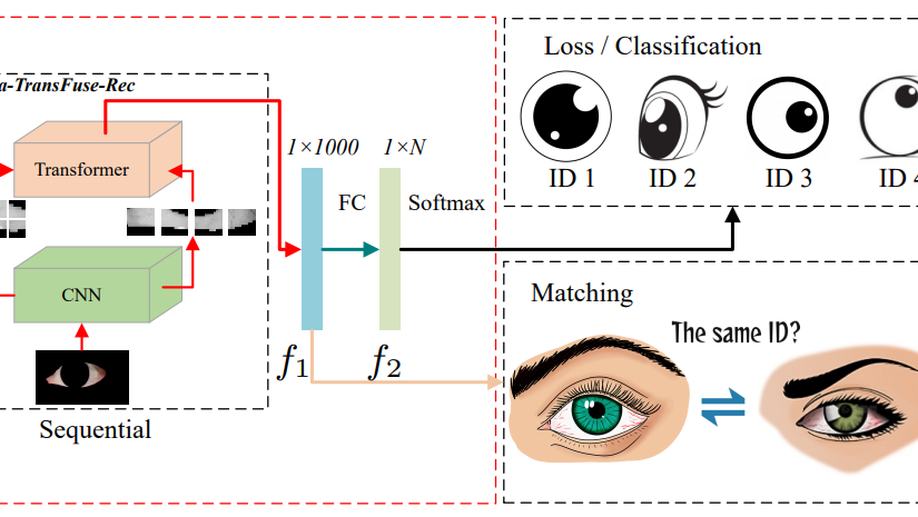
Sclera-TransFuse: Fusing Vision Transformer and CNN for Accurate Sclera Segmentation and Recognition
This paper investigates a deep learning based unified framework for accurate sclera segmentation and recognition, named Sclera-TransFuse. Unlike previous CNN-based methods, our framework incorporates Vision Transformer and CNN to extract complementary feature representations, which are beneficial to both subtasks. Specifically, for sclera segmentation, a novel two-stream hybrid model, referred to as Sclera-TransFuse-Seg, is developed to integrate classical ResNet-34 and recently emerging Swin Transformer encoders in parallel. The dual-encoders firstly extract coarse-and fine-grained feature representations at hierarchical stages, separately. Then a Cross-Domain Fusion (CDF) module based on information interaction and self-attention mechanism is introduced to efficiently fuse the multi-scale features extracted from dual-encoders. Finally, the fused features are progressively upsampled and aggregated to predict the sclera masks in the decoder meanwhile deep supervision strategies are employed to learn intermediate feature representations better and faster. With the results of sclera segmentation, the sclera ROI image is generated for sclera feature extraction. Additionally, a new sclera recognition model, termed as Sclera-TransFuse-Rec, is proposed by combining lightweight EfficientNet B0 and multi-scale Vision Transformer in sequential to encode local and global sclera vasculature feature representations. Extensive experiments on several publicly available databases suggest that our framework consistently achieves state-of-the-art performance on various sclera segmentation and recognition benchmarks, including the 8th Sclera Segmentation and Recognition Benchmarking Competition (SSRBC 2023). A UBIRIS.v2 subset of 683 eye images with manually labeled sclera masks, and our codes are publicly available to the community through https://github.com/lhqqq/Sclera-TransFuse.
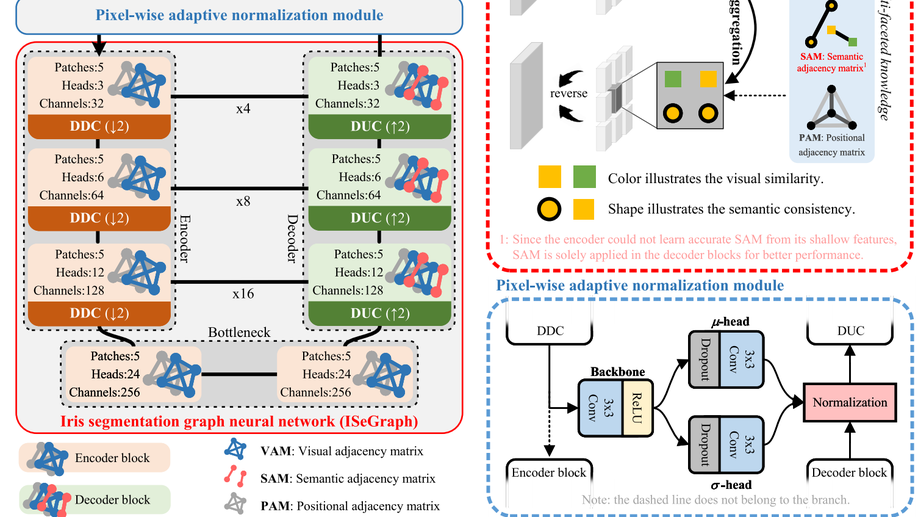
Multi-Faceted Knowledge-Driven Graph Neural Network for Iris Segmentation
Accurate iris segmentation, especially around the iris inner and outer boundaries, is still a formidable challenge. Pixels within these areas are difficult to semantically distinguish since they have similar visual characteristics and close spatial positions. To tackle this problem, the paper proposes an iris segmentation graph neural network (ISeGraph) for accurate segmentation. ISeGraph regards individual pixels as nodes within the graph and constructs self-adaptive edges according to multi-faceted knowledge, including visual similarity, positional correlation, and semantic consistency for feature aggregation. Specifically, visual similarity strengthens the connections between nodes sharing similar visual characteristics, while positional correlation assigns weights according to the spatial distance between nodes. In contrast to the above knowledge, semantic consistency maps nodes into a semantic space and learns pseudo-labels to define relationships based on label consistency. ISeGraph leverages multi-faceted knowledge to generate self-adaptive relationships for accurate iris segmentation. Furthermore, a pixel-wise adaptive normalization module is developed to increase the feature discriminability. It takes informative features in the shallow layer as a reference to improve the segmentation features from a statistical perspective. Experimental results on three iris datasets illustrate that the proposed method achieves superior performance in iris segmentation, increasing the segmentation accuracy in areas near the iris boundaries.
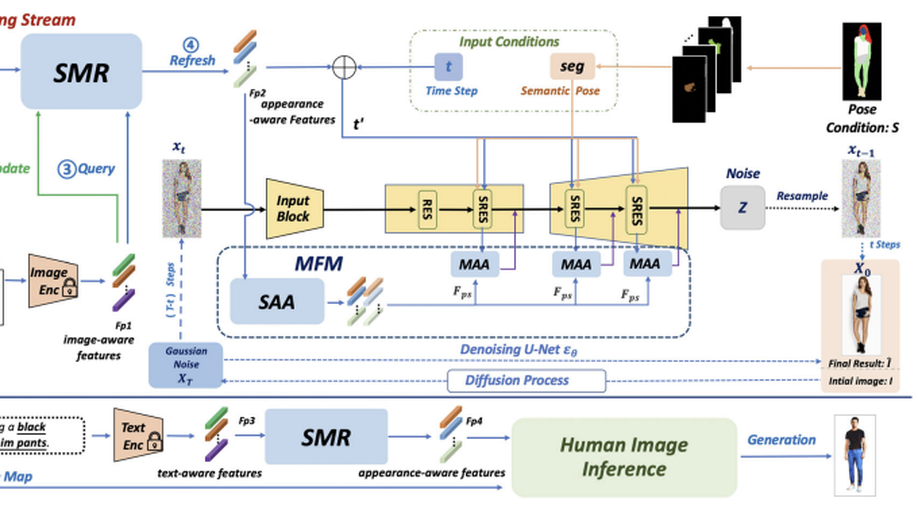
Open-Vocabulary Text-Driven Human Image Generation
Generating human images from open-vocabulary text descriptions is an exciting but challenging task. Previous methods (i.e., Text2Human) face two challenging problems: (1) they cannot well handle the open-vocabulary setting by arbitrary text inputs (i.e., unseen clothing appearances) and heavily rely on limited preset words (i.e., pattern styles of clothing appearances); (2) the generated human image is inaccuracy in open-vocabulary settings. To alleviate these drawbacks, we propose a flexible diffusion-based framework, namely HumanDiffusion, for open-vocabulary text-driven human image generation (HIG). The proposed framework mainly consists of two novel modules: the Stylized Memory Retrieval (SMR) module and the Multi-scale Feature Mapping (MFM) module. Encoded by the vision-language pretrained CLIP model, we obtain coarse features of the local human appearance. Then, the SMR module utilizes an external database that contains clothing texture details to refine the initial coarse features. Through SMR refreshing, we can achieve the HIG task with arbitrary text inputs, and the range of expression styles is greatly expanded. Later, the MFM module embedding in the diffusion backbone can learn fine-grained appearance features, which effectively achieves precise semantic-coherence alignment of different body parts with appearance features and realizes the accurate expression of desired human appearance. The seamless combination of the proposed novel modules in HumanDiffusion realizes the freestyle and high accuracy of text-guided HIG and editing tasks. Extensive experiments demonstrate that the proposed method can achieve state-of-the-art (SOTA) performance, especially in the open-vocabulary setting.
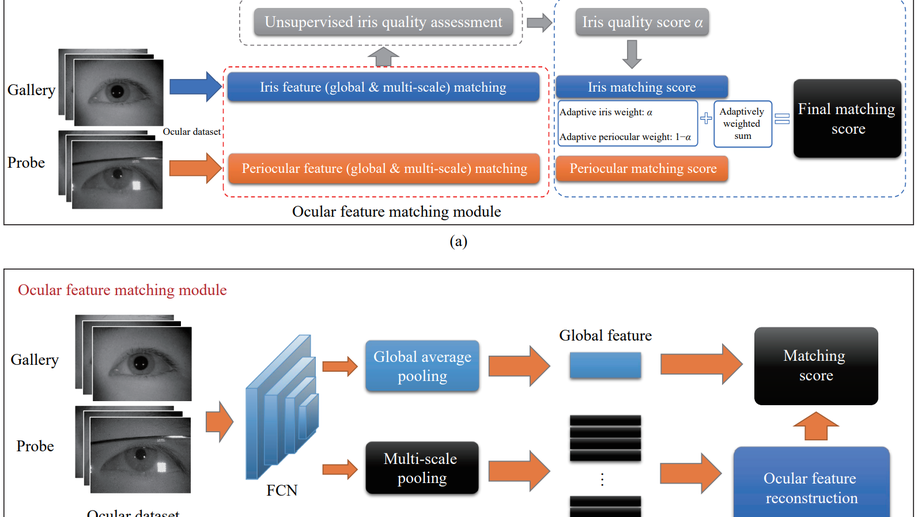
Boosting multi-modal ocular recognition via spatial feature reconstruction and unsupervised image quality estimation
In the daily application of an iris-recognition-at-a-distance (IAAD) system, many ocular images of low quality are acquired. As the iris part of these images is often not qualified for the recognition requirements, the more accessible periocular regions are a good complement for recognition. To further boost the performance of IAAD systems, a novel end-to-end framework for multi-modal ocular recognition is proposed. The proposed framework mainly consists of iris/periocular feature extraction and matching, unsupervised iris quality assessment, and a score-level adaptive weighted fusion strategy. First, ocular feature reconstruction (OFR) is proposed to sparsely reconstruct each probe image by high-quality gallery images based on proper feature maps. Next, a brand new unsupervised iris quality assessment method based on random multiscale embedding robustness is proposed. Different from the existing iris quality assessment methods, the quality of an iris image is measured by its robustness in the embedding space. At last, the fusion strategy exploits the iris quality score as the fusion weight to coalesce the complementary information from the iris and periocular regions. Extensive experimental results on ocular datasets prove that the proposed method is obviously better than unimodal biometrics, and the fusion strategy can significantly improve the recognition performance.
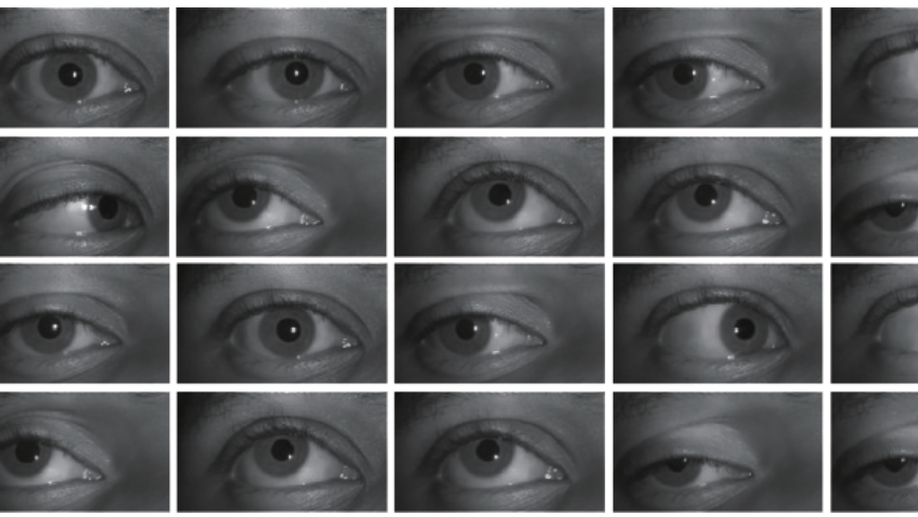
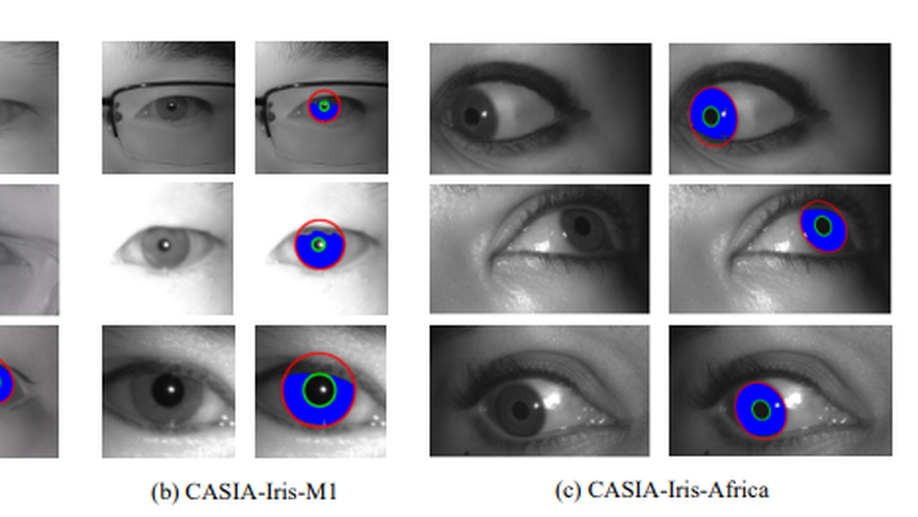
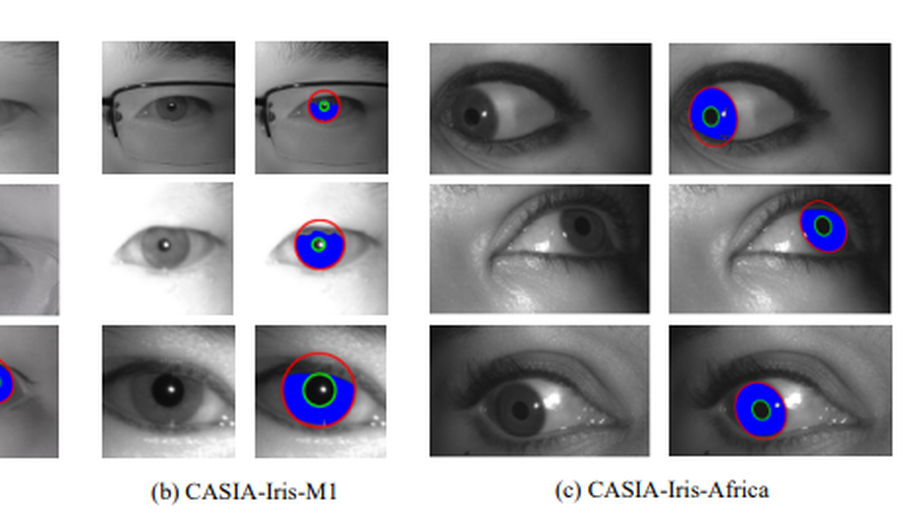
CASIA-Iris-Africa: A Large-scale African Iris Image Database
Iris biometrics is a phenotypic biometric trait that has proven to be agnostic to human natural physiological changes. Research on iris biometrics has progressed tremendously, partly due to publicly available iris databases. Various databases have been available to researchers that address pressing iris biometric challenges such as constraint, mobile, multispectral, synthetics, long-distance, contact lenses, liveness detection, etc. However, these databases mostly contain subjects of Caucasian and Asian docents with very few Africans. Despite many investigative studies on racial bias in face biometrics, very few studies on iris biometrics have been published, mainly due to the lack of racially diverse large-scale databases containing sufficient iris samples of Africans in the public domain. Furthermore, most of these databases contain a relatively small number of subjects and labelled images. This paper proposes a large-scale African database named Chinese Academy of Sciences Institute of Automation (CASIA)-Iris-Africa that can be used as a complementary database for the iris recognition community to mediate the effect of racial biases on Africans. The database contains 28 717 images of 1 023 African subjects (2 046 iris classes) with age, gender, and ethnicity attributes that can be useful in demographically sensitive studies of Africans. Sets of specific application protocols are incorporated with the database to ensure the database’s variability and scalability. Performance results of some open-source state-of-the-art (SOTA) algorithms on the database are presented, which will serve as baseline performances. The relatively poor performances of the baseline algorithms on the proposed database despite better performance on other databases prove that racial biases exist in these iris recognition algorithms.
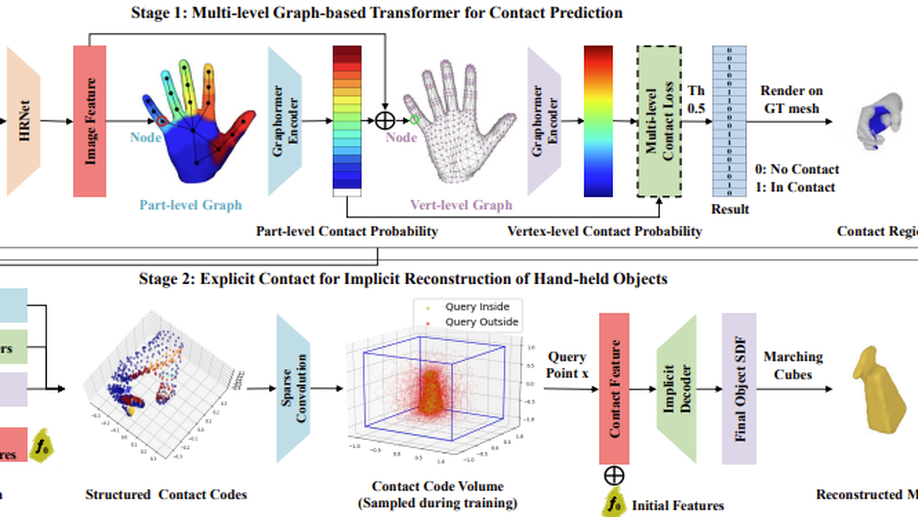
Learning Explicit Contact for Implicit Reconstruction of Hand-held Objects from Monocular Images
Reconstructing hand-held objects from monocular RGB images is an appealing yet challenging task. In this task, contacts between hands and objects provide important cues for recovering the 3D geometry of the hand-held objects. Though recent works have employed implicit functions to achieve impressive progress, they ignore formulating contacts in their frameworks, which results in producing less realistic object meshes. In this work, we explore how to model contacts in an explicit way to benefit the implicit reconstruction of hand-held objects. Our method consists of two components: explicit contact prediction and implicit shape reconstruction. In the first part, we propose a new subtask of directly estimating 3D hand-object contacts from a single image. The part-level and vertex-level graph-based transformers are cascaded and jointly learned in a coarse-to-fine manner for more accurate contact probabilities. In the second part, we introduce a novel method to diffuse estimated contact states from the hand mesh surface to nearby 3D space and leverage diffused contact probabilities to construct the implicit neural representation for the manipulated object. Benefiting from estimating the interaction patterns between the hand and the object, our method can reconstruct more realistic object meshes, especially for object parts that are in contact with hands. Extensive experiments on challenging benchmarks show that the proposed method outperforms the current state of the arts by a great margin. Our code is publicly available at https://junxinghu.github.io/projects/hoi.html.
Sensing Micro-Motion Human Patterns using Multimodal mmRadar and Video Signal for Affective and Psychological Intelligence
Affective and psychological perception are pivotal in human-machine interaction and essential domains within artificial intelligence. Existing physiological signal-based affective and psychological datasets primarily rely on contact-based sensors, potentially introducing extraneous affectives during the measurement process. Consequently, creating accurate non-contact affective and psychological perception datasets is crucial for overcoming these limitations and advancing affective intelligence. In this paper, we introduce the Remote Multimodal Affective and Psychological (ReMAP) dataset, for the first time, apply head micro-tremor (HMT) signals for affective and psychological perception. ReMAP features 68 participants and comprises two sub-datasets. The stimuli videos utilized for affective perception undergo rigorous screening to ensure the efficacy and universality of affective elicitation. Additionally, we propose a novel remote affective and psychological perception framework, leveraging multimodal complementarity and interrelationships to enhance affective and psychological perception capabilities. Extensive experiments demonstrate HMT as a “small yet powerful” physiological signal in psychological perception. Our method outperforms existing state-of-the-art approaches in remote affective recognition and psychological perception. The ReMAP dataset is publicly accessible at https://remap-dataset.github.io/ReMAP.
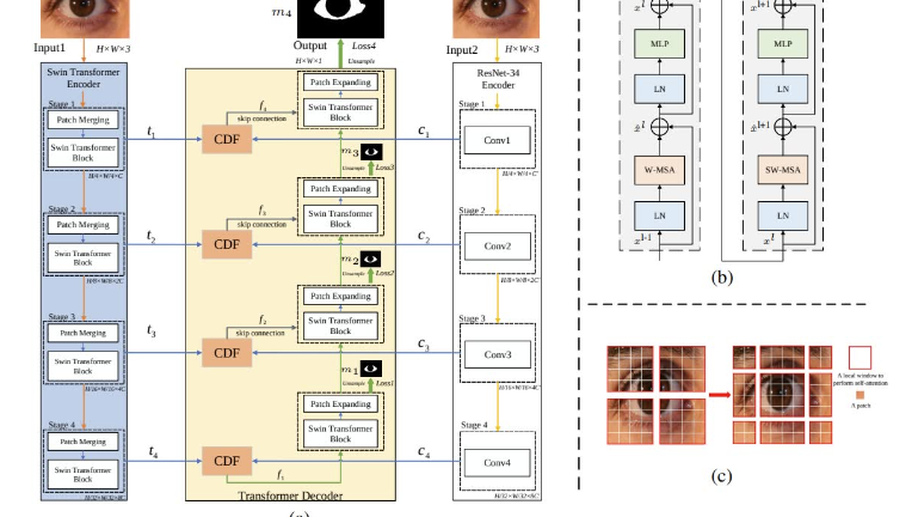
Sclera-TransFuse: Fusing Swin Transformer and CNN for Accurate Sclera Segmentation
Sclera segmentation is a crucial step in sclera recognition, which has been greatly advanced by Convolutional Neural Networks (CNNs). However, when dealing with non-ideal eye images, many existing CNN-based approaches are still prone to failure. One major reason is that due to the limited range of receptive fields, CNNs are difficult to effectively model global semantic relevance and thus robustly resist noise interference. To solve this problem, this paper proposes a novel two-stream hybrid model, named Sclera-TransFuse, to integrate classical ResNet-34 and recently emerging Swin Transformer encoders. Specially, the self-attentive Swin Transformer has shown a strong ability in capturing long-range spatial dependencies and has a hierarchical structure similar to CNNs. The dual encoders firstly extract coarse- and fine-grained feature representations at hierarchical stages, separately. Then a novel Cross-Domain Fusion (CDF) module based on information interaction and self-attention mechanism is introduced to efficiently fuse the multi-scale features extracted from dual encoders. Finally, the fused features are progressively upsampled and aggregated to predict the sclera masks in the decoder meanwhile deep supervision strategies are employed to learn intermediate feature representations better and faster. Experimental results show that Sclera-TransFuse achieves state-of-the-art performance on various sclera segmentation benchmarks. Additionally, a UBIRIS.v2 subset of 683 eye images with manually labeled sclera masks, and our codes are publicly available to the community through https://github.com/Ihqqq/Sclera-TransFuse.
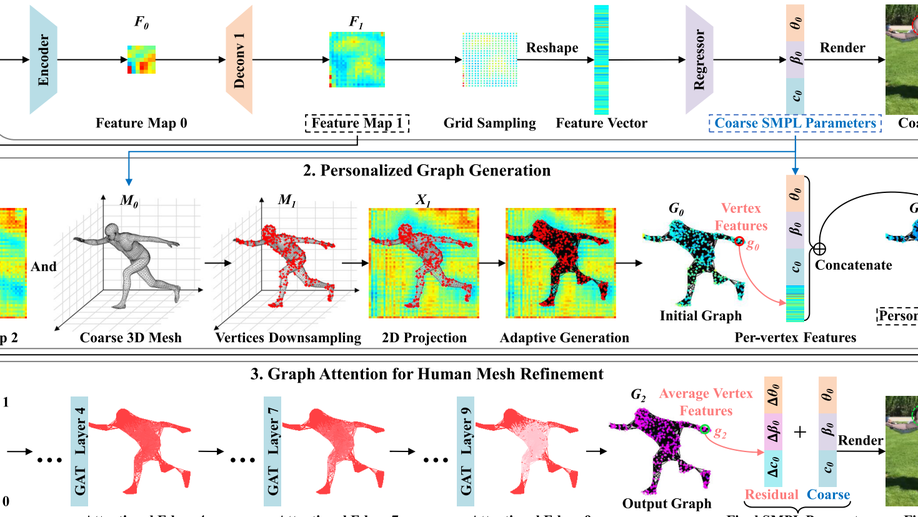
Personalized Graph Generation for Monocular 3D Human Pose and Shape Estimation
3D human pose and shape estimation from a single RGB image is an appealing yet challenging task. Due to the graph-like nature of human parametric models, a growing number of graph neural network-based approaches have been proposed and achieved promising results. However, existing methods build graphs for different instances based on the same template SMPL mesh, neglecting the geometric perception of individual properties. In this work, we propose an end-to-end method named Personalized Graph Generation (PGG) to construct the geometry-aware graph from an intermediate predicted human mesh. Specifically, a convolutional module initially regresses a coarse SMPL mesh tailored for each sample. Guided by the 3D structure of this personalized mesh, PGG extracts the local features from the 2D feature map. Then, these geometry-aware features are integrated with the specific coarse SMPL parameters as vertex features. Furthermore, a body-oriented adjacency matrix is adaptively generated according to the coarse mesh. It considers individual full-body relations between vertices, enhancing the perception of body geometry. Finally, a graph attentional module is utilized to predict the residuals to get the final results. Quantitative experiments across four benchmarks and qualitative comparisons on more datasets show that the proposed method outperforms state-of-the-art approaches for 3D human pose and shape estimation.
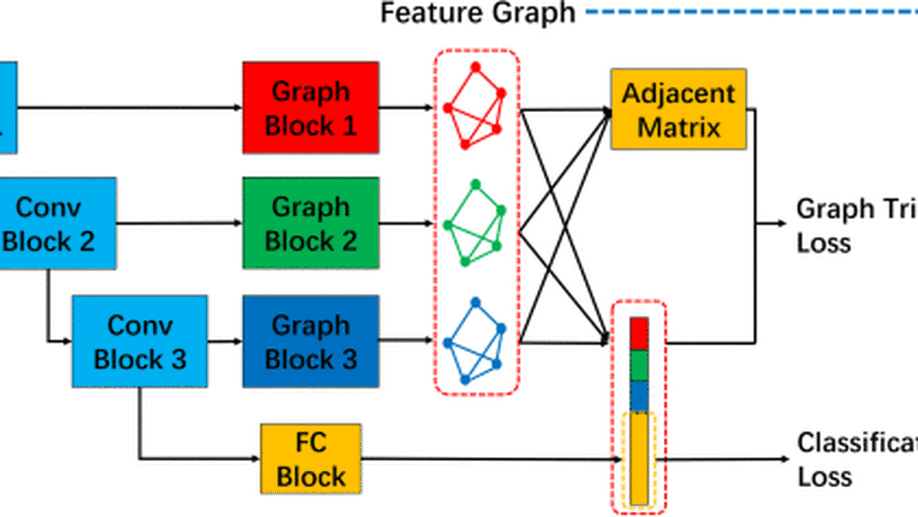
Multiscale Dynamic Graph Representation for Biometric Recognition with Occlusions
Occlusion is a common problem with biometric recognition in the wild. The generalization ability of CNNs greatly decreases due to the adverse effects of various occlusions. To this end, we propose a novel unified framework integrating the merits of both CNNs and graph models to overcome occlusion problems in biometric recognition, called multiscale dynamic graph representation (MS-DGR). More specifically, a group of deep features reflected on certain subregions is recrafted into a feature graph (FG). Each node inside the FG is deemed to characterize a specific local region of the input sample, and the edges imply the co-occurrence of non-occluded regions. By analyzing the similarities of the node representations and measuring the topological structures stored in the adjacent matrix, the proposed framework leverages dynamic graph matching to judiciously discard the nodes corresponding to the occluded parts. The multiscale strategy is further incorporated to attain more diverse nodes representing regions of various sizes. Furthermore, the proposed framework exhibits a more illustrative and reasonable inference by showing the paired nodes. Extensive experiments demonstrate the superiority of the proposed framework, which boosts the accuracy in both natural and occlusion-simulated cases by a large margin compared with that of baseline methods.
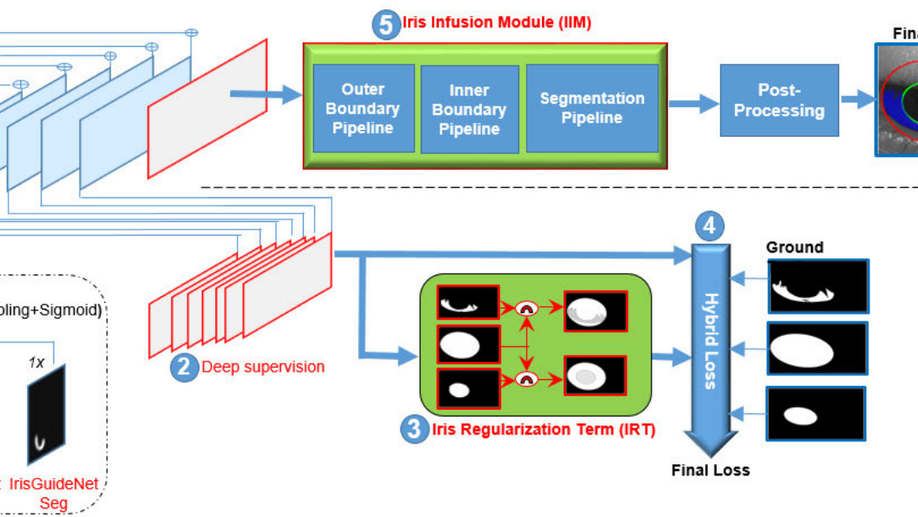
Iris-GuideNet: Guided Localisation and Segmentation Network for Unconstrained Iris Biometrics
In recent years, unconstrained iris biometrics has become more prevalent due to its wide range of user applications. However, it also presents numerous challenges to the Iris pre-processing task of Localization and Segmentation (ILS). Many ILS techniques have been proposed to address these challenges, among which the most effective is the CNN-based methods. Training the CNN is data-intensive, and most of the existing CNN-based ILS approaches do not incorporate iris-specific features that can reduce their data dependence, despite the limited labelled iris data in the available databases. These trained CNN models built upon these databases can be sub-optimal. Hence, this paper proposes a guided CNN-based ILS approach IrisGuideNet. IrisGuideNet involves incorporating novel iris-specific heuristics named Iris Regularization Term (IRT), deep supervision technique, and hybrid loss functions in the training pipeline, which guides the network and reduces the model data dependence. A novel Iris Infusion Module (IIM) that utilizes the geometrical relationships between the ILS outputs to refine the predicted outputs is introduced at network inference. The proposed model is trained and evaluated with various datasets. Experimental results show that IrisGuideNet has outperformed most models across all the database categories. The codes implementation of the proposed IrisGuideNet will be available at: https://github.com/mohdjawadi/IrisGuidenet.
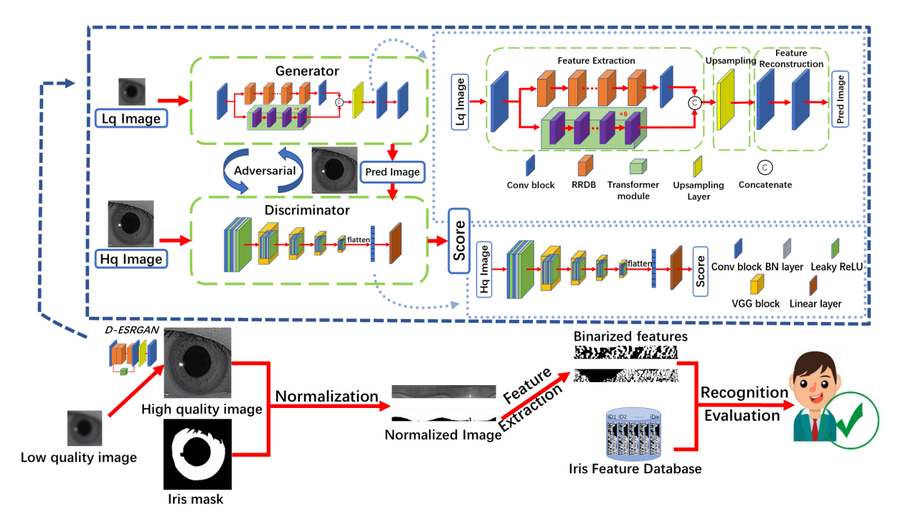
D-ESRGAN: A Dual-Encoder GAN with Residual CNN and Vision Transformer for Iris Image Super-Resolution
Iris images captured in less-constrained environments, especially at long distances often suffer from the interference of low resolution, resulting in the loss of much valid iris texture information for iris recognition. In this paper, we propose a dual-encoder super-resolution generative adversarial network (D-ESRGAN) for compensating texture lost of the raw image meanwhile maintaining the newly generated textures more natural. Specifically, the proposed D-ESRGAN not only integrates the residual CNN encoder to extract local features, but also employs an emerging vision transformer encoder to capture global associative information. The local and global features from two encoders are further fused for the subsequent reconstruction of high-resolution features. During the training, we develop a three-stage strategy to alleviate the problem that generative adversarial networks are prone to collapse. Moreover, to boost the iris recognition performance, we introduce a triplet loss to push away the distance of super-resolved iris images with different IDs, and pull the distance of super-resolved iris images with the same ID much closer. Experimental results on the public CASIA-Iris-distance and CASIA-Iris-M1 datasets show that D-ESRGAN archives better performance than state-of-the-art baselines in terms of both super-resolution image quality metrics and iris recognition metric.

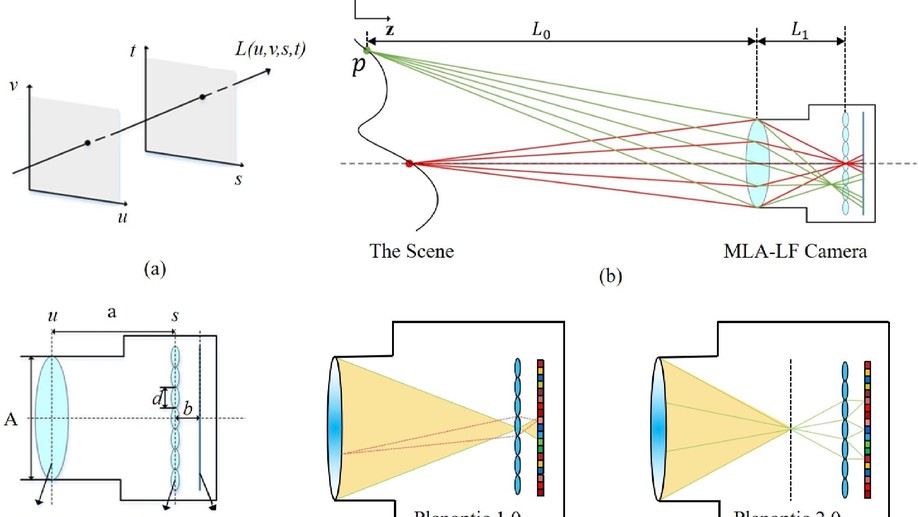
AIF-LFNet: All-in-Focus Light Field Super-Resolution Method Considering the Depth-Varying Defocus
As an aperture-divided computational imaging system, microlens array (MLA) -based light field (LF) imaging is playing an increasingly important role in computer vision. As the trade-off between the spatial and angular resolutions, deep learning (DL) -based image super-resolution (SR) methods have been applied to enhance the spatial resolution. However, in existing DL-based methods, the depth-varying defocus is not considered both in dataset development and algorithm design, which restricts many applications such as depth estimation and object recognition. To overcome this shortcoming, a super-resolution task that reconstructs all-in-focus high-resolution (HR) LF images from low-resolution (LR) LF images is proposed by designing a large dataset and proposing a convolutional neural network (CNN) -based SR method. The dataset is constructed by using Blender software, consisting of 150 light field images used as training data, and 15 light field images used as validation and testing data. The proposed network is designed by proposing the dilated deformable convolutional network (DCN) -based feature extraction block and the LF subaperture image (SAI) Deblur-SR block. The experimental results demonstrate that the proposed method achieves more appealing results both quantitatively and qualitatively.
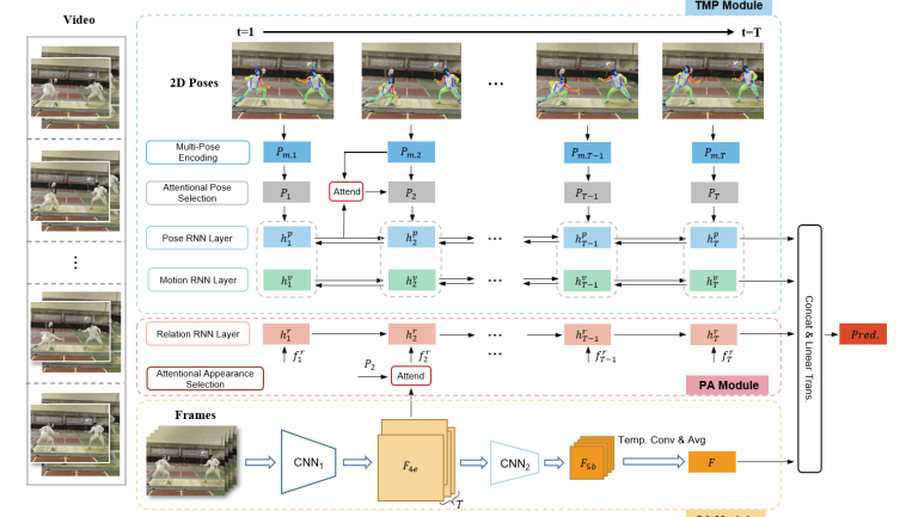
Pose-Appearance Relational Modeling for Video Action Recognition
Recent studies of video action recognition can be classified into two categories: the appearance-based methods and the pose-based methods. The appearance-based methods generally cannot model temporal dynamics of large motion well by virtue of optical flow estimation, while the pose-based methods ignore the visual context information such as typical scenes and objects, which are also important cues for action understanding. In this paper, we tackle these problems by proposing a Pose-Appearance Relational Network (PARNet), which models the correlation between human pose and image appearance, and combines the benefits of these two modalities to improve the robustness towards unconstrained real-world videos. There are three network streams in our model, namely pose stream, appearance stream and relation stream. For the pose stream, a Temporal Multi-Pose RNN module is constructed to obtain the dynamic representations through temporal modeling of 2D poses. For the appearance stream, a Spatial Appearance CNN module is employed to extract the global appearance representation of the video sequence. For the relation stream, a Pose-Aware RNN module is built to connect pose and appearance streams by modeling action-sensitive visual context information. Through jointly optimizing the three modules, PARNet achieves superior performances compared with the state-of-the-arts on both the pose-complete datasets (KTH, Penn-Action, UCF11) and the challenging pose-incomplete datasets (UCF101, HMDB51, JHMDB), demonstrating its robustness towards complex environments and noisy skeletons. Its effectiveness on NTU-RGBD dataset is also validated even compared with 3D skeleton-based methods. Furthermore, an appearance-enhanced PARNet equipped with a RGB-based I3D stream is proposed, which outperforms the Kinetics pre-trained competitors on UCF101 and HMDB51. The better experimental results verify the potentials of our framework by integrating various modules.
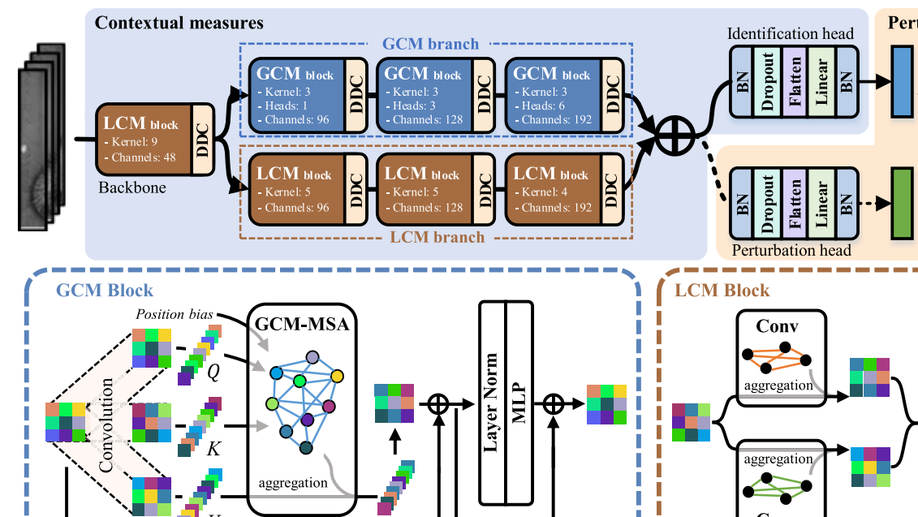
Contextual Measures for Iris Recognition
The iris patterns of the human contain a large amount of randomly distributed and irregularly shaped microstructures. These microstructures make the human iris informative biometric traits. To learn identity representation from them, this paper regards each iris region as a potential microstructure and proposes contextual measures (CM) to model the correlations between them. CM adopts two parallel branches to learn global and local contexts in iris image. The first one is the globally contextual measure branch. It measures the global context involving the relationships between all regions for feature aggregation and is robust to local occlusions. Besides, we improve its spatial perception considering the positional randomness of the microstructures. The other one is the locally contextual measure branch. This branch considers the role of local details in the phenotypic distinctiveness of iris patterns and learns a series of relationship atoms to capture contextual information from a local perspective. In addition, we develop the perturbation bottleneck to make sure that the two branches learn divergent contexts. It introduces perturbation to limit the information flow from input images to identity features, forcing CM to learn discriminative contextual information for iris recognition. Experimental results suggest that global and local contexts are two different clues critical for accurate iris recognition. The superior performance on four benchmark iris datasets demonstrates the effectiveness of the proposed approach in within-database and cross-database scenarios.
An Empirical Comparative Analysis of Africans with Asians Using DCNN Facial Biometric Models
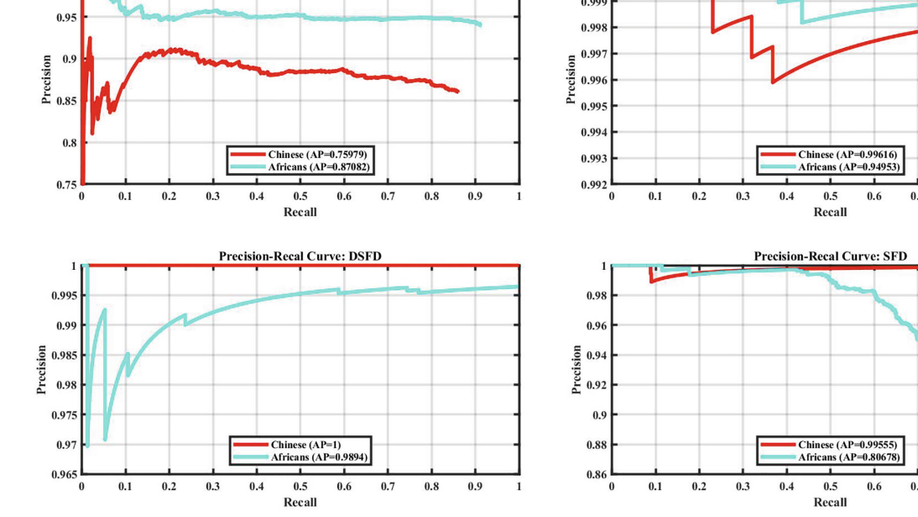
Recently, the problem of racial bias in facial biometric systems has generated considerable attention from the media and biometric community. Many investigative studies have been published on estimating the bias between Caucasians and Asians, Caucasians and Africans, and other racial comparisons. These studies have reported inferior performances of both Asians and Africans when compared to other races. However, very few studies have highlighted the comparative differences in performance as a function of race between Africans and Asians. More so, those previous studies were mainly concentrated on a single aspect of facial biometrics and were usually conducted with images potentially captured with multiple camera sensors, thereby compounding their findings. This paper presents a comparative racial bias study of Asians with Africans on various facial biometric tasks. The images used were captured with the same camera sensor and under controlled conditions. We examine the performances of many DCNN-based models on face detection, facial landmark detection, quality assessment, verification, and identification. The results suggested higher performance on the Asians compared to the Africans by most algorithms under the same imaging and testing conditions.

Exploring Bias in Sclera Segmentation Models: A Group Evaluation Approach
Bias and fairness of biometric algorithms have been key topics of research in recent years, mainly due to the societal, legal and ethical implications of potentially unfair decisions made by automated decision-making models. A considerable amount of work has been done on this topic across different biometric modalities, aiming at better understanding the main sources of algorithmic bias or devising mitigation measures. In this work, we contribute to these efforts and present the first study investigating bias and fairness of sclera segmentation models. Although sclera segmentation techniques represent a key component of sclera-based biometric systems with a considerable impact on the overall recognition performance, the presence of different types of biases in sclera segmentation methods is still underexplored. To address this limitation, we describe the results of a group evaluation effort (involving seven research groups), organized to explore the performance of recent sclera segmentation models within a common experimental framework and study performance differences (and bias), originating from various demographic as well as environmental factors. Using five diverse datasets, we analyze seven independently developed sclera segmentation models in different experimental configurations. The results of our experiments suggest that there are significant differences in the overall segmentation performance across the seven models and that among the considered factors, ethnicity appears to be the biggest cause of bias. Additionally, we observe that training with representative and balanced data does not necessarily lead to less biased results. Finally, we find that in general there appears to be a negative correlation between the amount of bias observed (due to eye color, ethnicity and acquisition device) and the overall segmentation performance, suggesting that advances in the field of semantic segmentation may also help with mitigating bias.
PDVN: A Patch-based Dual-view Network for Face Liveness Detection using Light Field Focal Stack
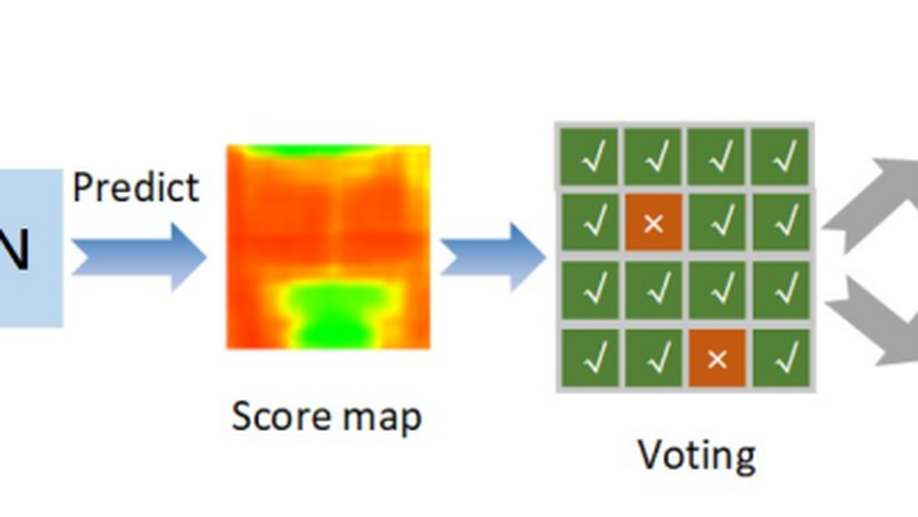
Light Field Focal Stack (LFFS) can be efficiently rendered from a light field (LF) image captured by plenoptic cameras. Differences in the 3D surface and texture of biometric samples are internally reflected in the defocus blur and local patterns between the rendered slices of LFFS. This unique property makes LFFS quite appropriate to differentiate presentation attack instruments (PAIs) from bona fide samples. A patch-based dual-view network (PDVN) is proposed in this paper to leverage the merits of LFFS for face presentation attack detection (PAD). First, original LFFS data are divided into various local patches along spatial dimensions, which distracts the model from learning the useless facial semantics and greatly relieve the problem of insufficient samples. The strategy of dual-view branches is innovatively proposed, wherein the original view and microscopic view can simultaneously contribute to liveness detection. Separable 3D convolution on the focal dimension is verified to be more effective than vanilla 3D convolution for extracting discriminative features from LFFS data. The voting mechanism on predictions of patch LFFS samples further strengthens the robustness of the proposed framework. PDVN is compared with other face PAD methods on IST LLFFSD dataset and achieves perfect performance, i.e., ACER drops to 0.
Combining 2D texture and 3D geometry features for Reliable iris presentation attack detection using light field focal stack
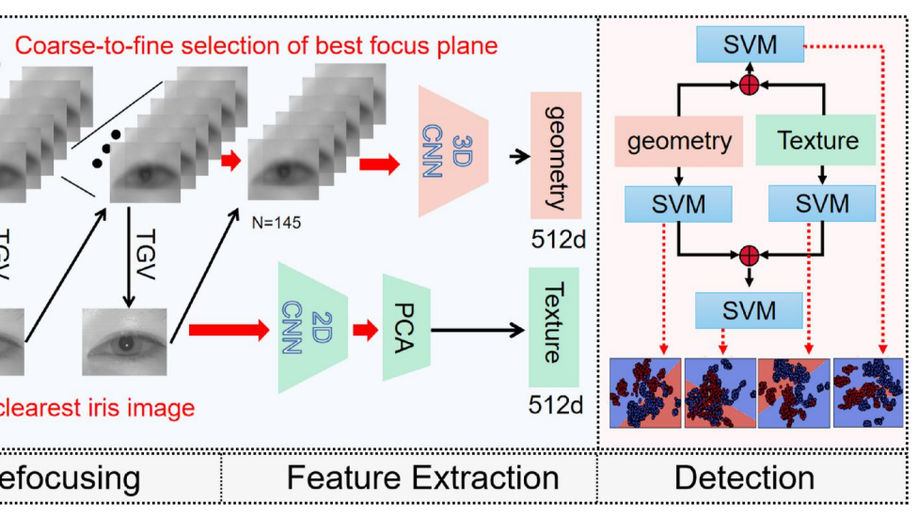
Iris presentation attack detection (PAD) is still an unsolved problem mainly due to the various spoof attack strategies and poor generalisation on unseen attackers. In this paper, the merits of both light field (LF) imaging and deep learning (DL) are leveraged to combine 2D texture and 3D geometry features for iris liveness detection. By exploring off-the-shelf deep features of planar-oriented and sequence-oriented deep neural networks (DNNs) on the rendered focal stack, the proposed framework excavates the differences in 3D geometric structure and 2D spatial texture between bona fide and spoofing irises captured by LF cameras. A group of pre-trained DL models are adopted as feature extractor and the parameters of SVM classifiers are optimised on a limited number of samples. Moreover, two-branch feature fusion further strengthens the framework’s robustness and reliability against severe motion blur, noise, and other degradation factors. The results of comparative experiments indicate that variants of the proposed framework significantly surpass the PAD methods that take 2D planar images or LF focal stack as input, even recent state-of-the-art (SOTA) methods fined-tuned on the adopted database. Presentation attacks, including printed papers, printed photos, and electronic displays, can be accurately detected without fine-tuning a bulky CNN. In addition, ablation studies validate the effectiveness of fusing geometric structure and spatial texture features. The results of multi-class attack detection experiments also verify the good generalisation ability of the proposed framework on unseen presentation attacks.
Perturbation Inactivation Based Adversarial Defense for Face Recognition
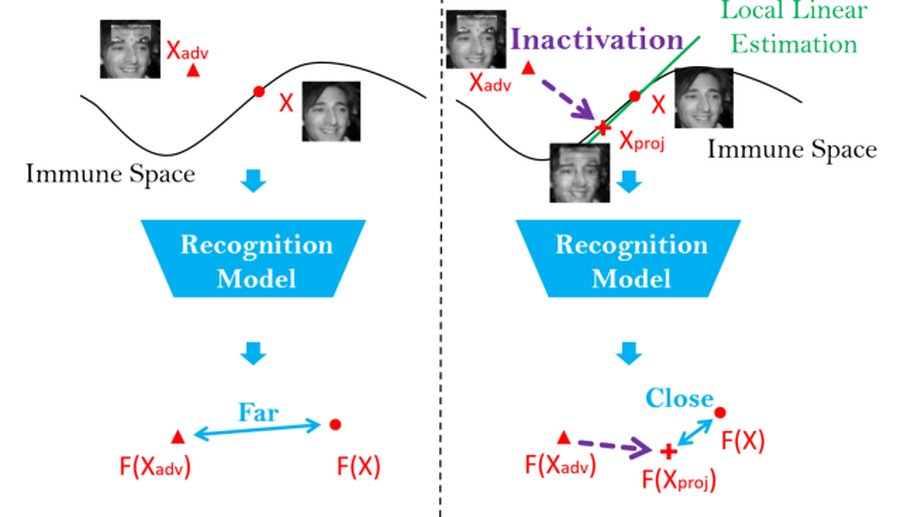
Deep learning-based face recognition models are vulnerable to adversarial attacks. To curb these attacks, most defense methods aim to improve the robustness of recognition models against adversarial perturbations. However, the generalization capacities of these methods are quite limited. In practice, they are still vulnerable to unseen adversarial attacks. Deep learning models are fairly robust to general perturbations, such as Gaussian noises. A straightforward approach is to inactivate the adversarial perturbations so that they can be easily handled as general perturbations. In this paper, a plug-and-play adversarial defense method, named perturbation inactivation (PIN), is proposed to inactivate adversarial perturbations for adversarial defense. We discover that the perturbations in different subspaces have different influences on the recognition model. There should be a subspace, called the immune space, in which the perturbations have fewer adverse impacts on the recognition model than in other subspaces. Hence, our method estimates the immune space and inactivates the adversarial perturbations by restricting them to this subspace. The proposed method can be generalized to unseen adversarial perturbations since it does not rely on a specific kind of adversarial attack method. This approach not only outperforms several state-of-the-art adversarial defense methods but also demonstrates a superior generalization capacity through exhaustive experiments. Moreover, the proposed method can be successfully applied to four commercial APIs without additional training, indicating that it can be easily generalized to existing face recognition systems.
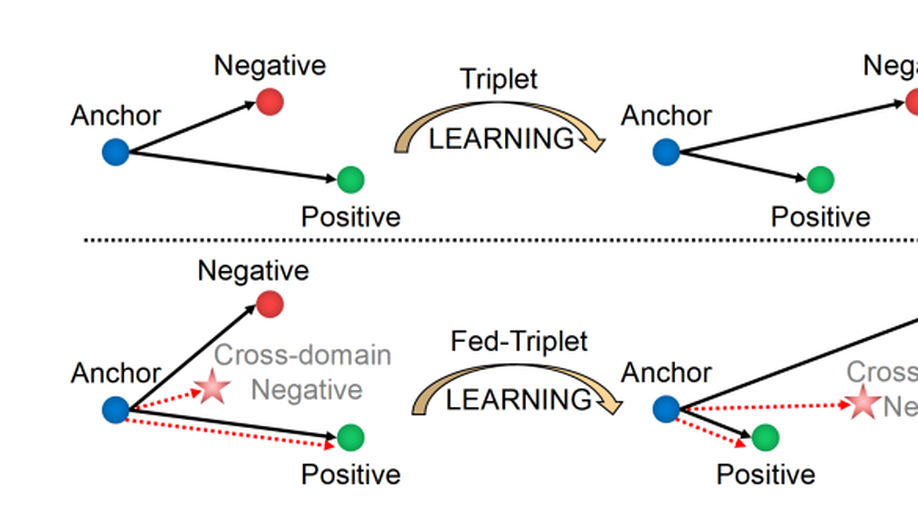
FedIris: Towards More Accurate and Privacy-Preserving Iris Recognition via Federated Template Communication
As biometric data undergo rapidly growing privacy concerns, building large-scale datasets has become more difficult. Unfortunately, current iris databases are mostly in small scale, e.g., thousands of iris images from hundreds of identities. What’s worse, the heterogeneity among decentralized iris datasets hinders the current deep learning (DL) frameworks from obtaining recognition performance with robust generalization. It motivates us to leverage the merits of federated learning (FL) to solve these problems. However, traditional FL algorithms often employ model sharing for knowledge transfer, wherein the simple averaging aggregation lacks interpretability, and divergent optimization directions of clients lead to performance degradation. To overcome this interference, we propose FedIris with solid theoretical foundations, which attempts to employ the iris template as the communication carrier and formulate federated triplet (Fed-Triplet) for knowledge transfer. Furthermore, the massive heterogeneity among iris datasets may induce negative transfer and unstable optimization. The modified Wasserstein distance is embedded into the FedTriplet loss to reweight global aggregation, which drives the clients with similar data distributions to contribute more mutually. Extensive experimental results demonstrate that the proposed FedIris outperforms SOLO training, model-sharing-based FL training, and even centralized training.
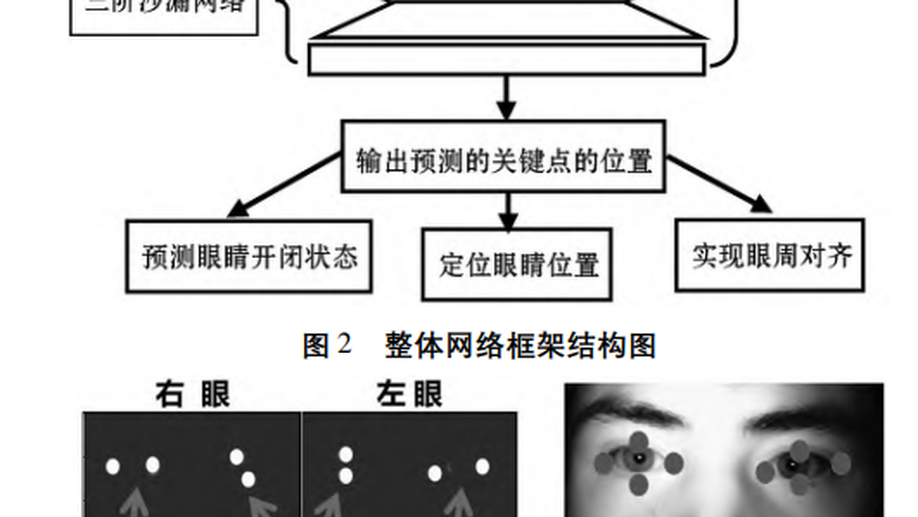
EYE LOCATION AND STATE ESTIMATION BASED ON LANDMARKS
Eye location and state estimation are key steps in the preprocessing of biometrics recognition such as iris, sclera and periocular. Eye images captured in the non-cooperative environments often suffer from serious occlusions and complex backgrounds. To solve this problem, this paper proposes a robust and accurate single-stage framework based on eye landmarks to detect eye key points and estimate the left, right and open and closed states of eyes. In order to train and evaluate the proposed model, a new OCE-1000 dataset was created and manually labeled with eight key points, open and close state for left and right eyes of each image. Experimental results show that the proposed model achieves 98% accuracy of landmark location and 97% accuracy of eye state estimation on OCE-1000 dataset.
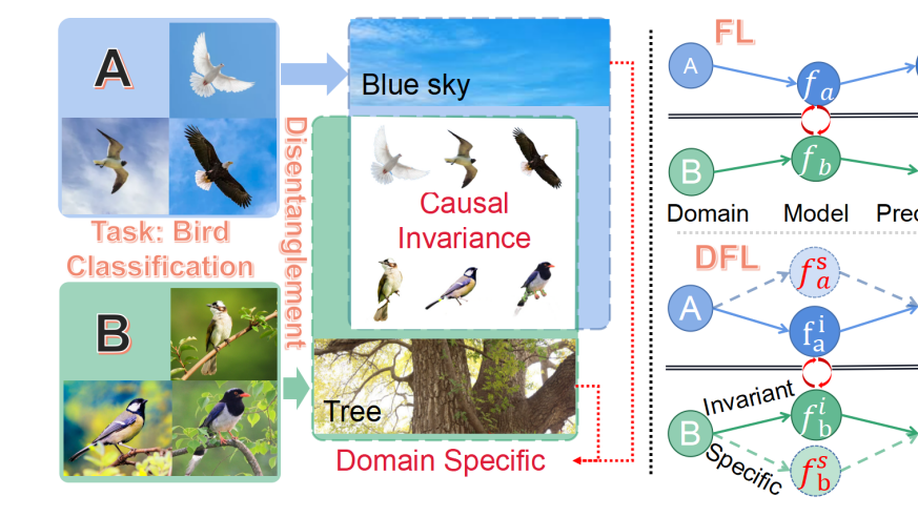
Disentangled Federated Learning for Tackling Attributes Skew via Invariant Aggregation and Diversity Transferring
Attributes skew hinders the current federated learning (FL) frameworks from consistent optimization directions among the clients, which inevitably leads to performance reduction and unstable convergence. The core problems lie in that: 1) Domain-specific attributes, which are non-causal and only locally valid, are indeliberately mixed into global aggregation. 2) The one-stage optimizations of entangled attributes cannot simultaneously satisfy two conflicting objectives, i.e., generalization and personalization. To cope with these, we proposed disentangled federated learning (DFL) to disentangle the domain-specific and cross-invariant attributes into two complementary branches, which are trained by the proposed alternating local-global optimization independently. Importantly, convergence analysis proves that the FL system can be stably converged even if incomplete client models participate in the global aggregation, which greatly expands the application scope of FL. Extensive experiments verify that DFL facilitates FL with higher performance, better interpretability, and faster convergence rate, compared with SOTA FL methods on both manually synthesized and realistic attributes skew datasets.
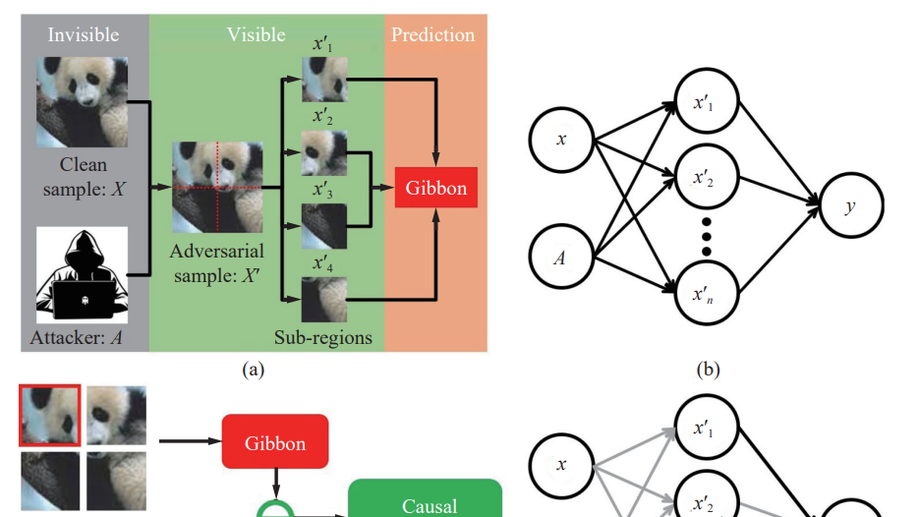
Towards Interpretable Defense Against Adversarial Attacks via Causal Inference
Deep learning-based models are vulnerable to adversarial attacks. Defense against adversarial attacks is essential for sensitive and safety-critical scenarios. However, deep learning methods still lack effective and efficient defense mechanisms against adversarial attacks. Most of the existing methods are just stopgaps for specific adversarial samples. The main obstacle is that how adversarial samples fool the deep learning models is still unclear. The underlying working mechanism of adversarial samples has not been well explored, and it is the bottleneck of adversarial attack defense. In this paper, we build a causal model to interpret the generation and performance of adversarial samples. The self-attention/transformer is adopted as a powerful tool in this causal model. Compared to existing methods, causality enables us to analyze adversarial samples more naturally and intrinsically. Based on this causal model, the working mechanism of adversarial samples is revealed, and instructive analysis is provided. Then, we propose simple and effective adversarial sample detection and recognition methods according to the revealed working mechanism. The causal insights enable us to detect and recognize adversarial samples without any extra model or training. Extensive experiments are conducted to demonstrate the effectiveness of the proposed methods. Our methods outperform the state-of-the-art defense methods under various adversarial attacks.
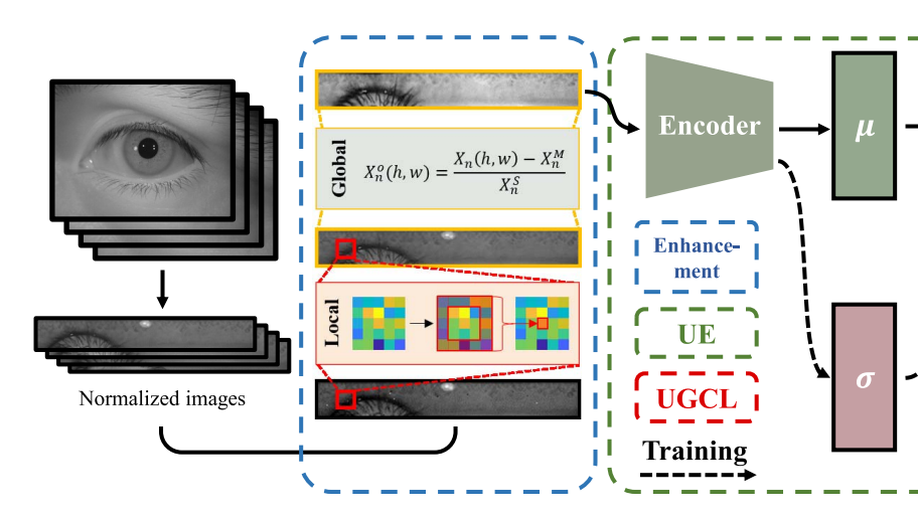
Towards More Discriminative and Robust Iris Recognition by Learning Uncertain Factors
The uncontrollable acquisition process limits the performance of iris recognition. In the acquisition process, various inevitable factors, including eyes, devices, and environment, hinder the iris recognition system from learning a discriminative identity representation. This leads to severe performance degradation. In this paper, we explore uncertain acquisition factors and propose uncertainty embedding (UE) and uncertainty-guided curriculum learning (UGCL) to mitigate the influence of acquisition factors. UE represents an iris image using a probabilistic distribution rather than a deterministic point (binary template or feature vector) that is widely adopted in iris recognition methods. Specifically, UE learns identity and uncertainty features from the input image, and encodes them as two independent components of the distribution, mean and variance. Based on this representation, an input image can be regarded as an instantiated feature sampled from the UE, and we can also generate various virtual features through sampling. UGCL is constructed by imitating the progressive learning process of newborns. Particularly, it selects virtual features to train the model in an easy-to-hard order at different training stages according to their uncertainty. In addition, an instance-level enhancement method is developed by utilizing local and global statistics to mitigate the data uncertainty from image noise and acquisition conditions in the pixel-level space. The experimental results on six benchmark iris datasets verify the effectiveness and generalization ability of the proposed method on same-sensor and cross-sensor recognition.
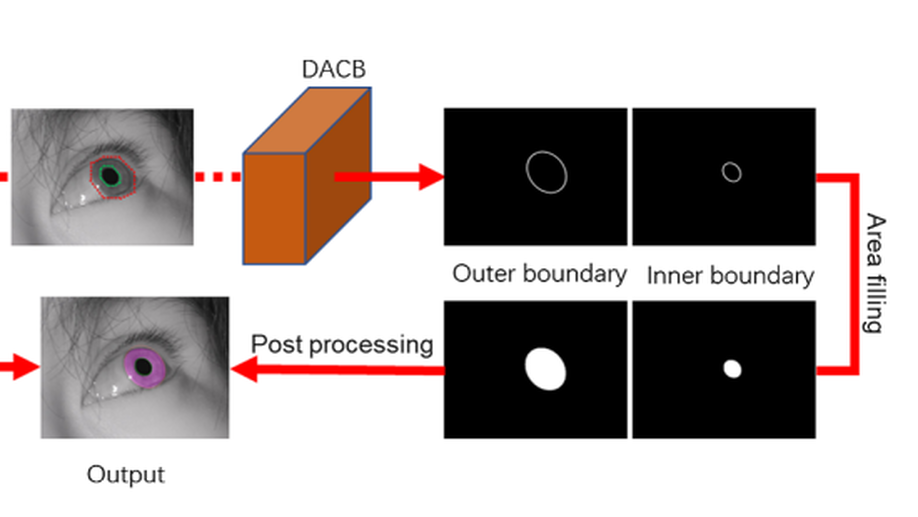
Multitask deep active contour-based iris segmentation for off-angle iris images
Iris recognition has been considered as a secure and reliable biometric technology. However, iris images are prone to off-angle or are partially occluded when captured with fewer user cooperations. As a consequence, iris recognition especially iris segmentation suffers a serious performance drop. To solve this problem, we propose a multitask deep active contour model for off-angle iris image segmentation. Specifically, the proposed approach combines the coarse and fine localization results. The coarse localization detects the approximate position of the iris area and further initializes the iris contours through a series of robust preprocessing operations. Then, iris contours are represented by 40 ordered isometric sampling polar points and thus their corresponding offset vectors are regressed via a convolutional neural network for multiple times to obtain the precise inner and outer boundaries of the iris. Next, the predicted iris boundary results are regarded as a constraint to limit the segmentation range of noise-free iris mask. Besides, an efficient channel attention module is introduced in the mask prediction to make the network focus on the valid iris region. A differentiable, fast, and efficient SoftPool operation is also used in place of traditional pooling to keep more details for more accurate pixel classification. Finally, the proposed iris segmentation approach is combined with off-the-shelf iris feature extraction models including traditional OM and deep learning-based FeatNet for iris recognition. The experimental results on two NIR datasets CASIA-Iris-off-angle, CASIA-Iris-Africa, and a VIS dataset SBVPI show that the proposed approach achieves a significant performance improvement in the segmentation and recognition for both regular and off-angle iris images.
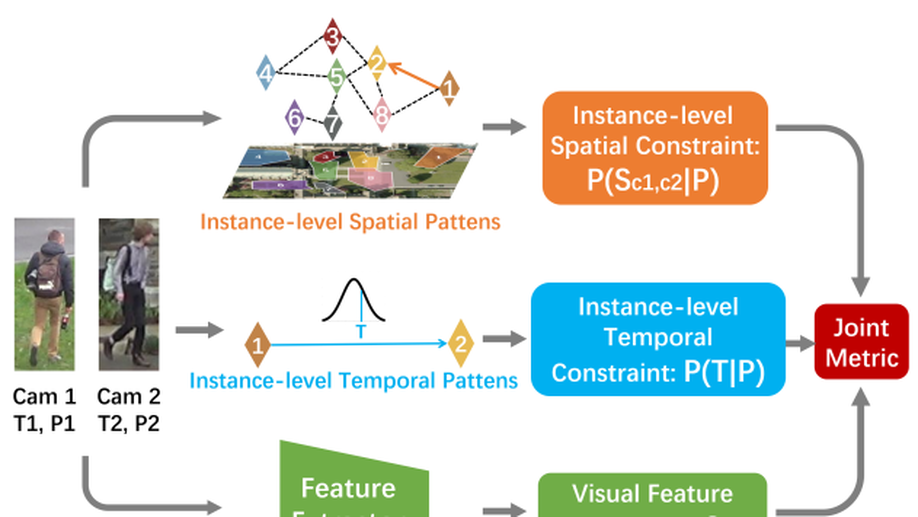
Learning Instance-level Spatial-Temporal Patterns for Person Re-identification
Person re-identification (Re-ID) aims to match pedestrians under dis-joint cameras. Most Re-ID methods formulate it as visual representation learning and image search, and its accuracy is consequently affected greatly by the search space. Spatial-temporal information has been proven to be efficient to filter irrelevant negative samples and significantly improve Re-ID accuracy. However, existing spatial-temporal person Re-ID methods are still rough and do not exploit spatial-temporal information sufficiently. In this paper, we propose a novel instance-level and spatial-temporal disentangled Re-ID method (InSTD), to improve Re-ID accuracy. In our proposed framework, personalized information such as moving direction is explicitly considered to further narrow down the search space. Besides, the spatial-temporal transferring probability is disentangled from joint distribution to marginal distribution, so that outliers can also be well modeled. Abundant experimental analyses on two datasets are presented, which demonstrates the superiority and provides more insights into our method. The proposed method achieves mAP of 90.8% on Market-1501 and 89.1% on DukeMTMC-reID, improving from the baseline 82.2% and 72.7%, respectively. Besides, in order to provide a better benchmark for person re-identification, we release a cleaned data list of DukeMTMC-reID with this paper: https://github.com/RenMin1991/cleaned-DukeMTMC-reID.
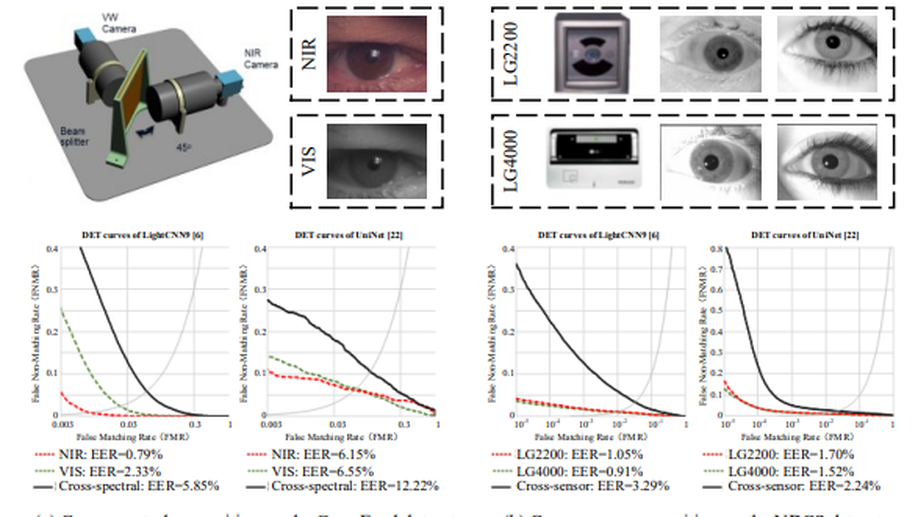
Cross-spectral Iris Recognition by Learning Device-specific Band
Cross-spectral recognition is still an open challenge in iris recognition. In cross-spectral iris recognition, there exist distinct device-specific bands between near-infrared (NIR) and visible (VIS) images, resulting in the distribution gap between samples from different spectra and thus severe degradation in recognition performance. To tackle this problem, we propose a new cross-spectral iris recognition method to learn spectral-invariant features by estimating device-specific bands. In the proposed method, Gabor Trident Network (GTN) first utilizes the Gabor function’s priors to perceive iris textures under different spectra, and then codes the device-specific band as the residual component to assist the generation of spectral-invariant features. By investigating the device-specific band, GTN effectively reduces the impact of device-specific bands on identity features. Besides, we make three efforts to further reduce the distribution gap. First, Spectral Adversarial Network (SAN) adopts a class-level adversarial strategy to align feature distributions. Second, Sample-Anchor (SA) loss upgrades triplet loss by pulling samples to their class center and pushing away from other class centers. Third, we develop a higher-order alignment loss to measures the distribution gap according to space bases and distribution shapes. Extensive experiments on five iris datasets demonstrate the efficacy of our proposed method for cross-spectral iris recognition.
Iris Normalization Beyond Appr-Circular Parameter Estimation
The requirement to recognize the iris image of low-quality is rapidly increasing with the practical application of iris recognition, especially the urgent need for high-throughput or applications in covert situations. The appr-circle fitting can not meet the needs due to the high time cost and non-accurate boundary estimation during the normalization process. Furthermore, the appr-circular hypothesis of iris and pupil is not entirely established due to the squint and occlusion in non-cooperative environments. To mitigate this problem, a multi-mask normalization without appr-circular parameter estimation is proposed to make full use of the segmented masks, which provide robust pixel-level iris boundaries. It bridges the segmentation and feature extraction to recognize the low-quality iris, which is thrown directly by the traditional methods. Thus, the complex samples with no appr-circular iris or massive occlusions can be recognized correctly. The extensive experiments are conducted on the representative and challenging databases to verify the generalization and the accuracy of the proposed iris normalization method. Besides, the throughput rate is significantly improved.
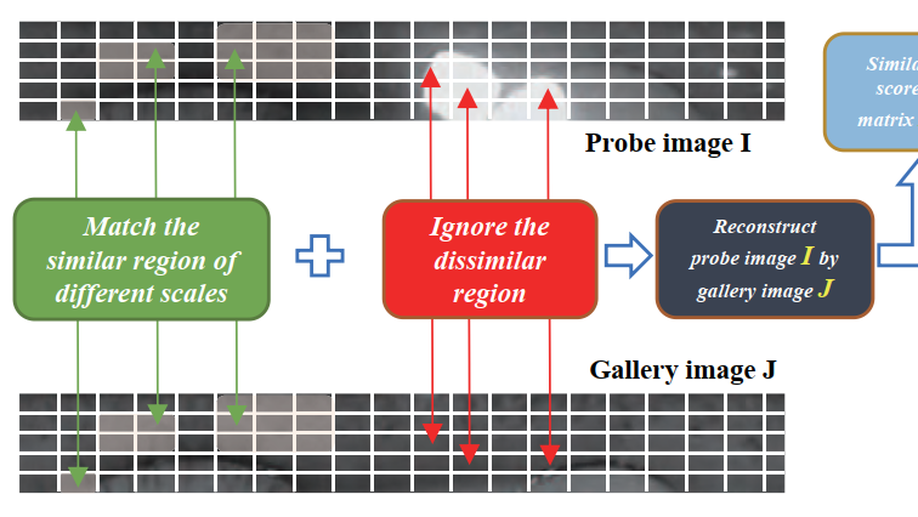
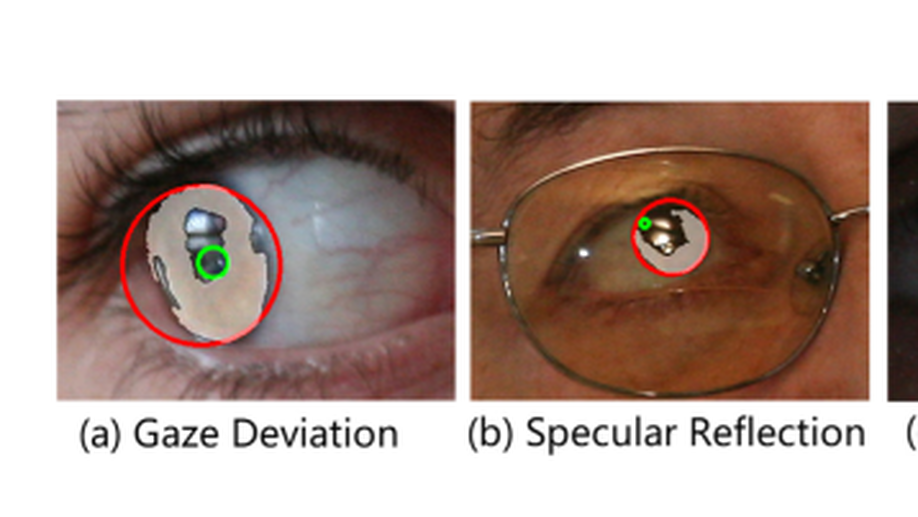
Flexible Iris Matching Based on Spatial Feature Reconstruction
In an iris recognition-at-a-distance (IAAD) system used in surveillance scenarios, the camera usually captures a large number of low-quality images. These images exhibit partial occlusions due to eyelids and eyelashes, specular reflections, and severe deformations caused by pupil dilations and contractions. Recognizing these low-quality images is a challenging yet dominant problem in IAAD. To mitigate this issue, current iris recognition systems mostly filter out low-quality images by using strict criteria based on image quality evaluation. This strategy, however, wastes device capabilities and produces low throughput of subjects. Other systems require highly cooperative users. In this work, we propose a novel occlusion-robust, deformation-robust, and alignment-free framework for low-quality iris matching, which integrates the merits of deep features and sparse representation in an end-to-end learning process known as iris spatial feature reconstruction (ISFR). Here each probe image can be sparsely reconstructed on the basis of appropriate feature maps from gallery high-quality images. ISFR uses the error from robust reconstruction over spatial pyramid features to measure similarities between two iris images, which naturally avoids the time-consuming alignment step. In summary, the distinctiveness of deep features, the robustness of sparse reconstruction, and the flexibility of multiscale matching strategy are unified in a general framework to attain more accurate and reasonable iris matching. Extensive experimental results on four public iris image databases demonstrate that the proposed method significantly outperforms both traditional and deep learning-based iris recognition methods.

A Large-scale Database for Less Cooperative Iris Recognition
Since the outbreak of the COVID-19 pandemic, iris recognition has been used increasingly as contactless and unaffected by face masks. Although less user cooperation is an urgent demand for existing systems, corresponding manually annotated databases could hardly be obtained. This paper presents a large-scale database of near-infrared iris images named CASIA-Iris-Degradation Version 1.0 (DV1), which consists of 15 subsets of various degraded images, simulating less cooperative situations such as illumination, off-angle, occlusion, and nonideal eye state. A lot of open-source segmentation and recognition methods are compared comprehensively on the DV1 using multiple evaluations, and the best among them are exploited to conduct ablation studies on each subset. Experimental results show that even the best deep learning frameworks are not robust enough on the database, and further improvements are recommended for challenging factors such as half-open eyes, off-angle, and pupil dilation. Therefore, we publish the DV1 with manual annotations online to promote iris recognition.
NIR Iris Challenge Evaluation in Non-cooperative Environments: Segmentation and Localization
For iris recognition in non-cooperative environments, iris segmentation has been regarded as the first most important challenge still open to the biometric community, affecting all downstream tasks from normalization to recognition. In recent years, deep learning technologies have gained significant popularity among various computer vision tasks and also been introduced in iris biometrics, especially iris segmentation. To investigate recent developments and attract more interest of researchers in the iris segmentation method, we organized the 2021 NIR Iris Challenge Evaluation in Non-cooperative Environments: Segmentation and Localization (NIR-ISL 2021) at the 2021 International Joint Conference on Biometrics (IJCB 2021). The challenge was used as a public platform to assess the performance of iris segmentation and localization methods on Asian and African NIR iris images captured in non-cooperative environments. The three best-performing entries achieved solid and satisfactory iris segmentation and localization results in most cases, and their code and models have been made publicly available for reproducibility research.
NIR Iris Challenge Evaluation in Non-cooperative Environments: Segmentation and Localization
For iris recognition in non-cooperative environments, iris segmentation has been regarded as the first most important challenge still open to the biometric community, affecting all downstream tasks from normalization to recognition. In recent years, deep learning technologies have gained significant popularity among various computer vision tasks and also been introduced in iris biometrics, especially iris segmentation. To investigate recent developments and attract more interest of researchers in the iris segmentation method, we organized the 2021 NIR Iris Challenge Evaluation in Non-cooperative Environments: Segmentation and Localization (NIR-ISL 2021) at the 2021 International Joint Conference on Biometrics (IJCB 2021). The challenge was used as a public platform to assess the performance of iris segmentation and localization methods on Asian and African NIR iris images captured in non-cooperative environments. The three best-performing entries achieved solid and satisfactory iris segmentation and localization results in most cases, and their code and models have been made publicly available for reproducibility research.

CASIA-Face-Africa: A Large-Scale African Face Image Database
Face recognition is a popular and well-studied area with wide applications in our society. However, racial bias had been proven to be inherent in most State Of The Art (SOTA) face recognition systems. Many investigative studies on face recognition algorithms have reported higher false positive rates of African subjects cohorts than the other cohorts. Lack of large-scale African face image databases in public domain is one of the main restrictions in studying the racial bias problem of face recognition. To this end, we collect a face image database namely CASIA-Face-Africa which contains 38,546 images of 1,183 African subjects. Multi-spectral cameras are utilized to capture the face images under various illumination settings. Demographic attributes and facial expressions of the subjects are also carefully recorded. For landmark detection, each face image in the database is manually labeled with 68 facial keypoints. A group of evaluation protocols are constructed according to different applications, tasks, partitions and scenarios. The performances of SOTA face recognition algorithms without re-training are reported as baselines. The proposed database along with its face landmark annotations, evaluation protocols and preliminary results form a good benchmark to study the essential aspects of face biometrics for African subjects, especially face image preprocessing, face feature analysis and matching, facial expression recognition, sex/age estimation, ethnic classification, face image generation, etc. The database can be downloaded from our website.
生物特征识别学科发展报告
从手机解锁、小区门禁到餐厅吃饭、超市收银,再到高铁进站、机场安检以及医院看病,人脸、虹膜和指纹等生物特征已成为人们进入万物互联世界的数字身份证。生物特征识别赋予机器自动探测、捕获、处理、分析和识别数字化生理或行为信号的高级智能,是一个典型而又复杂的模式识别问题,一直处于人工智能技术发展前沿,在新一代人工智能规划、“互联网+”行动计划等国家战略中具有重要地位。由于生物特征识别涉及公众利益攸关的隐私、道德和法律等问题,近期也引起了广泛的社会关注。本文系统综述了生物特征识别学科发展现状、新兴方向、存在问题和可行思路,深入梳理了人脸、虹膜、指纹、掌纹、静脉、声纹、步态、行人重识别以及多模态融合识别的研究进展,以人脸为例重点介绍了生物特征识别领域近些年受到关注的新方向——对抗攻击和防御、深度伪造和反伪造,最后剖析总结了生物特征识别领域存在的3大挑战问题——“感知盲区”、“决策误区”和“安全红区”。本文认为必须变革和创新生物特征的传感、认知和安全机制,才有可能取得复杂场景生物识别学术研究和技术应用的根本性突破,破除现有生物识别技术的弊端,朝着“可感”、“可知”和“可信”的新一代生物特征识别总体目标发展。
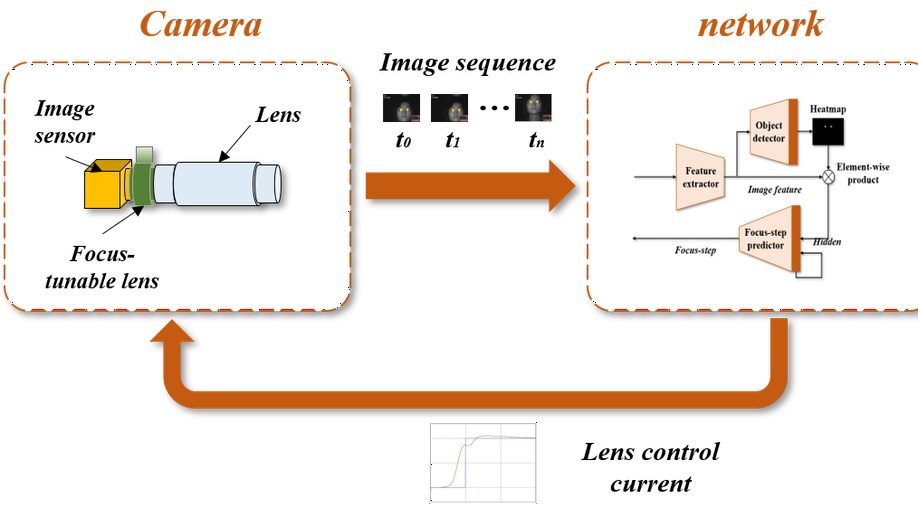
An End-to-End Autofocus Camera for Iris on the Move
For distant iris recognition, a long focal length lens is generally used to ensure the resolution of iris images, which reduces the depth of field and leads to potential defocus blur. To accommodate users at different distances, it is necessary to control focus quickly and accurately. While for users in motion, it is expected to maintain the correct focus on the iris area continuously. In this paper, we introduced a novel rapid autofocus camera for active refocusing of the iris area of the moving objects using a focus-tunable lens. Our end-to-end computational algorithm can predict the best focus position from one single blurred image and generate the proper lens diopter control signal automatically. This scene-based active manipulation method enables real-time focus tracking of the iris area of a moving object. We built a testing bench to collect real-world focal stacks for evaluation of the autofocus methods. Our camera has reached an autofocus speed of over 50 fps. The results demonstrate the advantages of our proposed camera for biometric perception in static and dynamic scenes. The code is available at https://github.com/Debatrix/AquulaCam
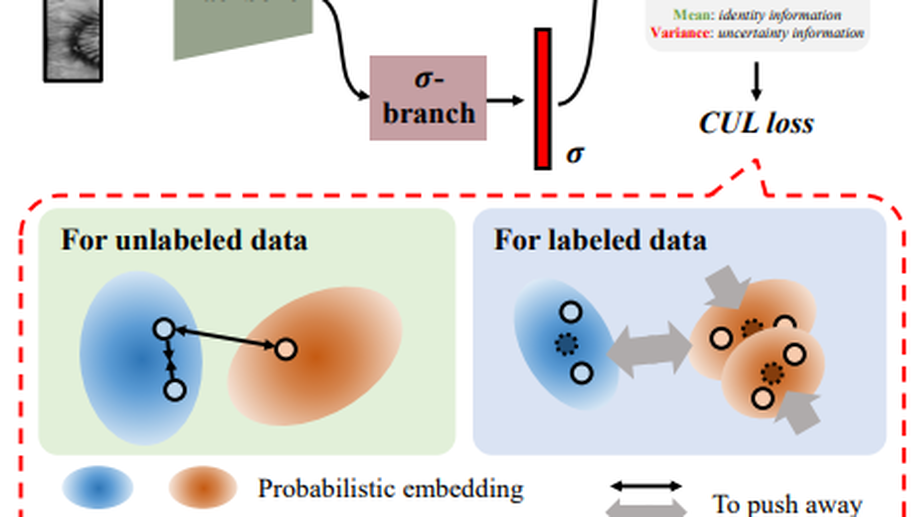
Contrastive Uncertainty Learning for Iris Recognition with Insufficient Labeled Samples
Cross-database recognition is still an unavoidable challenge when deploying an iris recognition system to a new environment. In the paper, we present a compromise problem that resembles the real-world scenario, named iris recognition with insufficient labeled samples. This new problem aims to improve the recognition performance by utilizing partially-or un-labeled data. To address the problem, we propose Contrastive Uncertainty Learning (CUL) by integrating the merits of uncertainty learning and contrastive self-supervised learning. CUL makes two efforts to learn a discriminative and robust feature representation. On the one hand, CUL explores the uncertain acquisition factors and adopts a probabilistic embedding to represent the iris image. In the probabilistic representation, the identity information and acquisition factors are disentangled into the mean and variance, avoiding the impact of uncertain acquisition factors on the identity information. On the other hand, CUL utilizes probabilistic embeddings to generate virtual positive and negative pairs. Then CUL builds its contrastive loss to group the similar samples closely and push the dissimilar samples apart. The experimental results demonstrate the effectiveness of the proposed CUL for iris recognition with insufficient labeled samples.
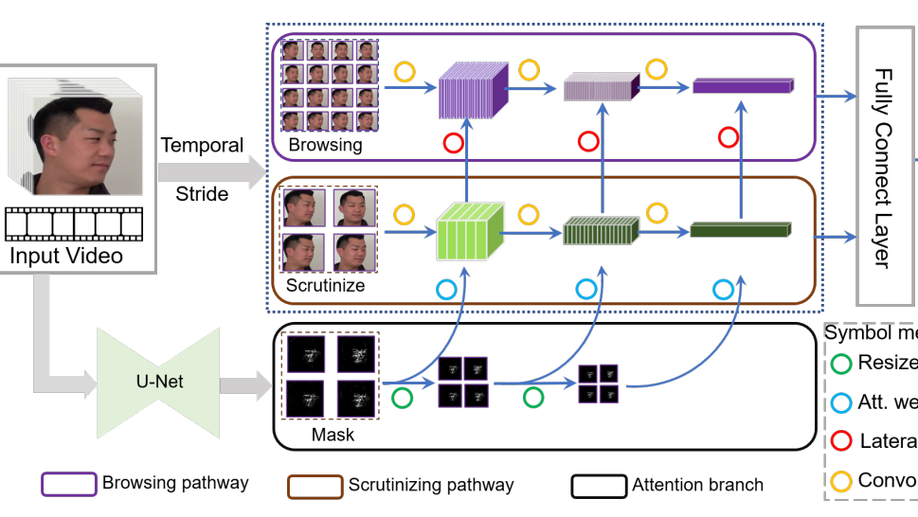
Bita-Net: Bi-temporal Attention Network for Facial Video Forgery Detection
Deep forgery detection on video data has attracted remarkable research attention in recent years due to its potential in defending forgery attacks. However, existing methods either only focus on the visual evidence within individual images, or are too sensitive to fluctuations across frames. To address these issues, this paper propose a novel model, named Bita-Net, to detect forgery faces in video data. The network design of Bita-Net is inspired by the mechanism of how human beings detect forgery data, i.e. browsing and scrutinizing, which is reflected by the two-pathway architecture of Bita-Net. Concretely, the browsing pathway scans the entire video at a high frame rate to check the temporal consistency, while the scrutinizing pathway focuses on analyzing key frames of the video at a lower frame rate. Furthermore, an attention branch is introduced to improve the forgery detection ability of the scrutinizing pathway. Extensive experiment results demonstrate the effectiveness and generalization ability of Bita-Net on various popular face forensics detection datasets, including FaceForensics++, CelebDF, DeepfakeTIMIT and UADFV.
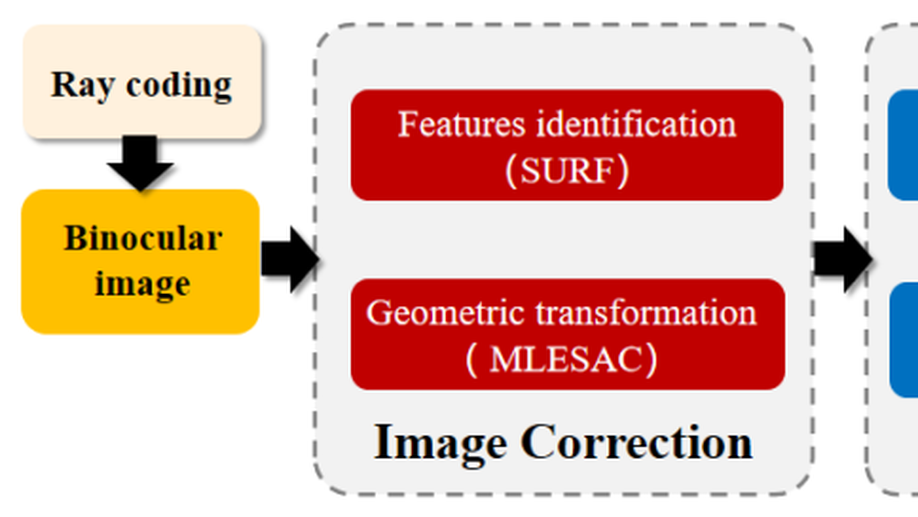
Avoiding Spectacles Reflections on Iris Images Using A Ray-tracing Method
Spectacles reflection removal is a challenging problem in iris recognition research. The reflection of the spectacles usually contaminates the iris image acquired under infrared illumination. The intense light reflection caused by the active light source makes reflection removal more challenging than normal scenes since important iris texture features are entirely obscured. Eliminating unnecessary reflections can effectively improve iris recognition system performance. This paper proposes a spectacle reflection removal algorithm based on ray coding and ray tracking to remove spectacle reflection in iris images. By decoding the light source’s encoded light beam, the iris imaging device eliminates most of the stray light. Our binocular imaging device tracks the light path to obtain parallax information and realizes reflected light spot removal through image fusion. We designed a prototype system to verify our proposed method in this paper. This method can effectively eliminate reflections without changing iris texture and improve iris recognition in complex scenarios.
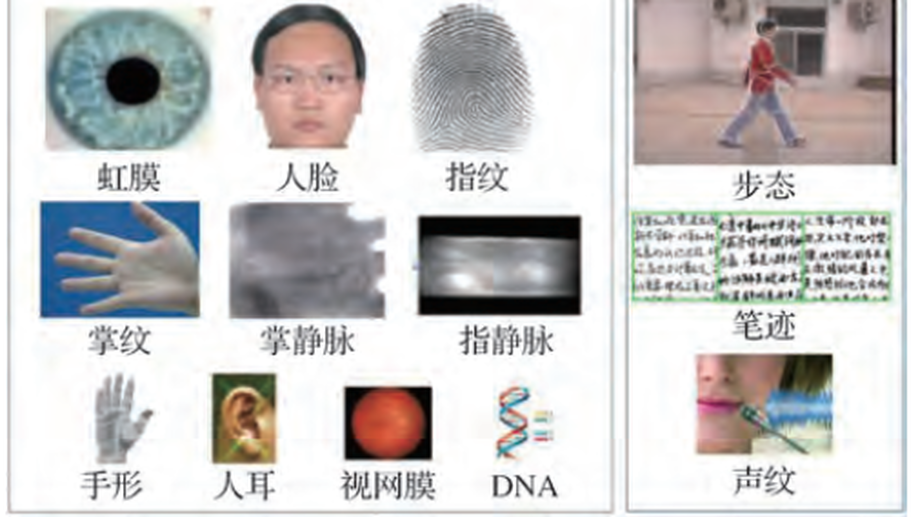
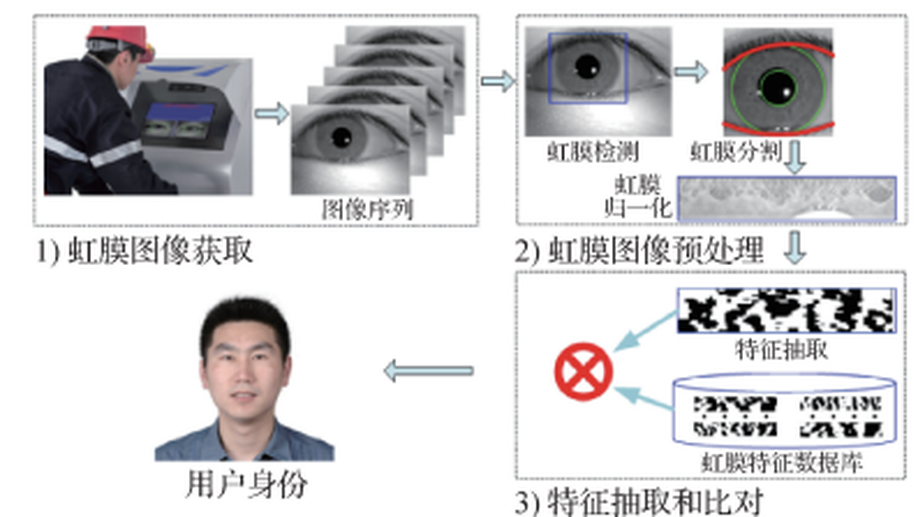
Overview of biometrics research
Biometrics, such as face, iris, and fingerprint recognition, have become digital identity proof for people to enter the “Internet of Everything” . For example, one may be asked to present the biometric identifier for unlocking mobile, passing access control at airports, rail stations, and paying at supermarkets or restaurants. Biometric recognition empowers a machine to automatically detect, capture, process, analyze, and recognize digital physiological or behavioral signals with advanced intelligence. Thus, biometrics requires interdisciplinary research of science and technology involving optical engineering, mechanical engineering, electronic engineering, machine learning, pattern recognition, computer vision, digital image processing, signal analysis, cognitive science, neuroscience, human-computer interaction, and information security. Biometrics is a typical and complex pattern recognition problem, which is a frontier research direction of artificial intelligence. In addition, biometric identification is a key development area of Chinese strategies, such as the Development Plan on the New Generation of Artificial Intelligence and the “Internet Plus” Action Plan. The development of biometric identification involves public interest, privacy, ethics, and law issues; thus, it has also attracted widespread attention from the society. This article systematically reviews the development status, emerging directions, existing problems, and feasible ideas of biometrics and comprehensively summarizes the research progress of face, iris, fingerprint, palm print, finger / palm vein, voiceprint, gait recognition, person reidentification, and multimodal biometric fusion. The overview of face recognition includes face detection, facial landmark localization, 2D face feature extraction and recognition, 3D face feature extraction and recognition, facial liveness detection, and face video based biological signal measurement. The overview of iris recognition includes iris image acquisition, iris segmentation and localization, iris liveness detection, iris image quality assessment, iris feature extraction, heterogeneous iris recognition, fusion of iris and other modalities, security problems of iris biometrics, and future trends of iris recognition. The overview of fingerprint recognition includes latent fingerprint recognition, fingerprint liveness detection, distorted fingerprint recognition, 3D fingerprint capturing, and challenges and trends of fingerprint biometrics. The overview of palm print recognition mainly introduces databases, feature models, matching strategies, and open problems of palm print biometrics. The overview of vein biometrics introduces main datasets and algorithms for finger vein, dorsal hand vein, and palm vein, and then points out the remaining unsolved problems and development trend of vein recognition. The overview of gait recognition introduces model-based and model-free methods for gait feature extraction and matching. The overview of person reidentification introduces research progress of new methods under supervised, unsupervised and weakly supervised conditions, gait database virtualization, generative gait models, and new problems, such as clothes changing, black clothes, and partial occlusions. The overview of voiceprint recognition introduces the history of speaker recognition, robustness of voiceprint, spoofing attacks, and antispoofing methods. The overview of multibiometrics introduces image-level, feature-level, score-level, and decision-level information fusion methods and deep learning based fusion approaches. Taking face as the exemplar biometric modality, new research directions that have received great attentions in the field of biometric recognition in recent years, i. e. , adversarial attack and defense as well as Deepfake and anti-Deepfake, are also introduced. Finally, we analyze and summarize the three major challenges in the field of biometric recognition——— “ the blind spot of biometric sensors”, “ the decision errors of biometric algorithms” and “the red zone of biometric security” . Therefore, the sensing, cognition, and security mechanisms of biometrics are necessary to achieve a fundamental breakthrough in the academic research and technologies applications of biometrics in complex scenarios to address the shortcomings of the existing biometric technologies and to move towards the overall goal of developing a new generation of “ perceptible, “ robust”, and “ trustworthy” biometric identification technology.
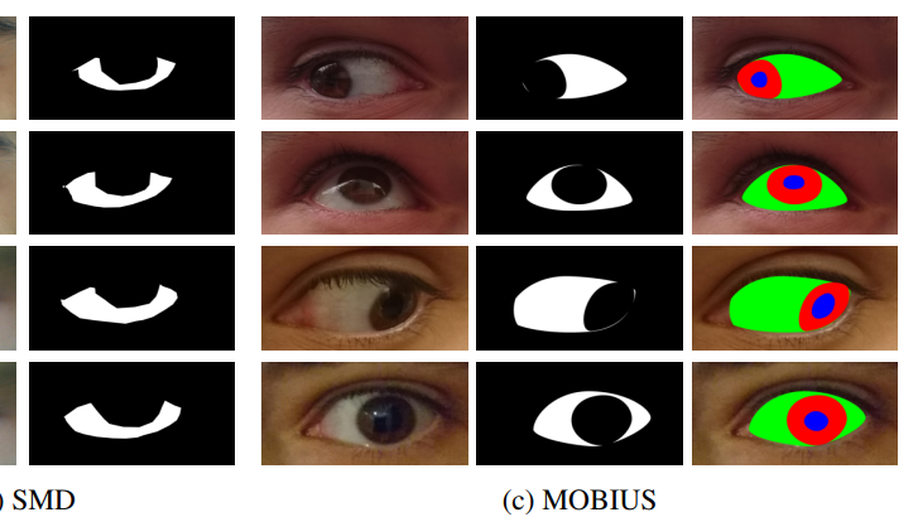
SSBC 2020: Sclera Segmentation Benchmarking Competition in the Mobile Environment
The paper presents a summary of the 2020 Sclera Segmentation Benchmarking Competition (SSBC), the 7th in the series of group benchmarking efforts centred around the problem of sclera segmentation. Different from previous editions, the goal of SSBC 2020 was to evaluate the performance of sclera-segmentation models on images captured with mobile devices. The competition was used as a platform to assess the sensitivity of existing models to i) differences in mobile devices used for image capture and ii) changes in the ambient acquisition conditions. 26 research groups registered for SSBC 2020, out of which 13 took part in the final round and submitted a total of 16 segmentation models for scoring. These included a wide variety of deep-learning solutions as well as one approach based on standard image processing techniques. Experiments were conducted with three recent datasets. Most of the segmentation models achieved relatively consistent performance across images captured with different mobile devices (with slight differences across devices), but struggled most with low-quality images captured in challenging ambient conditions, i.e., in an indoor environment and with poor lighting.
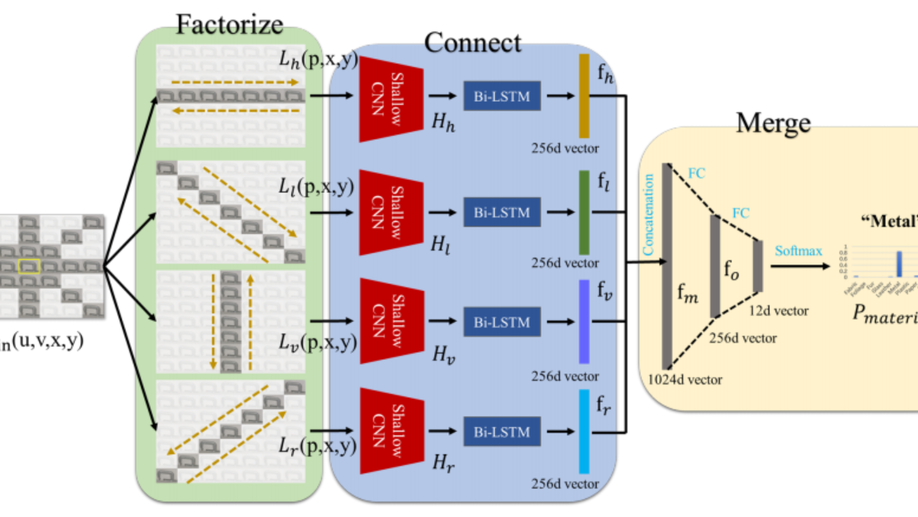
A Novel Deep-learning Pipeline for Light Field Image Based Material Recognition
The primitive basis of image based material recognition builds upon the fact that discrepancies in the reflectances of distinct materials lead to imaging differences under multiple viewpoints. LF cameras possess coherent abilities to capture multiple sub-aperture views (SAIs) within one exposure, which can provide appropriate multi-view sources for material recognition. In this paper, a unified Factorize-Connect-Merge (FCM) deep-learning pipeline is proposed to solve problems of light field image based material recognition. 4D light-field data as input is initially decomposed into consecutive 3D light-field slices. Shallow CNN is leveraged to extract low-level visual features of each view inside these slices. As to establish correspondences between these SAIs, Bidirectional Long-Short Term Memory (Bi-LSTM) network is built upon these low-level features to model the imaging differences. After feature selection including concatenation and dimension reduction, effective and robust feature representations for material recognition can be extracted from 4D light-field data. Experimental results indicate that the proposed pipeline can obtain remarkable performances on both tasks of single-pixel material classification and whole-image material segmentation. In addition, the proposed pipeline can potentially benefit and inspire other researchers who may also take LF images as input and need to extract 4D light-field representations for computer vision tasks such as object classification, semantic segmentation and edge detection.

High-fidelity View Synthesis for Light Field Imaging with Extended Pseudo 4DCNN
Multi-view properties of light field (LF) imaging enable exciting applications such as auto-refocusing, depth estimation and 3D reconstruction. However, limited angular resolution has become the main bottleneck of microlens-based plenoptic cameras towards more practical vision applications. Existing view synthesis methods mainly break the task into two steps, i.e. depth estimating and view warping, which are usually inefficient and produce artifacts over depth ambiguities. We have proposed an end-to-end deep learning framework named Pseudo 4DCNN to solve these problems in a conference paper. Rethinking on the overall paradigm, we further extend pseudo 4DCNN and propose a novel loss function which is applicable for all tasks of light field reconstruction i.e. EPI Structure Preserving (ESP) loss function. This loss function is proposed to attenuate the blurry edges and artifacts caused by averaging effect of L2 norm based loss function. Furthermore, the extended Pseudo 4DCNN is compared with recent state-of-the-art (SOTA) approaches on more publicly available light field databases, as well as self-captured light field biometrics and microscopy datasets. Experimental results demonstrate that the proposed framework can achieve better performances than vanilla Pseudo 4DCNN and other SOTA methods, especially in the terms of visual quality under occlusions. The source codes and self-collected datasets for reproducibility are available online.
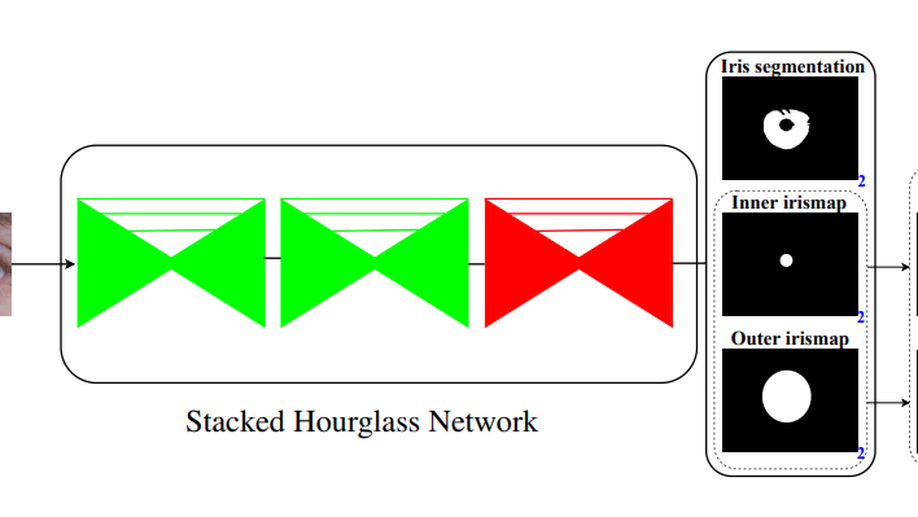
A Lightweight Multi-Label Segmentation Network for Mobile Iris Biometrics
This paper proposes a novel, lightweight deep convolutional neural network specifically designed for iris segmentation of noisy images acquired by mobile devices. Unlike previous studies, which only focused on improving the accuracy of segmentation mask using the popular CNN technology, our method is a complete end-to-end iris segmentation solution, i.e., segmentation mask and parameterized pupillary and limbic boundaries of the iris are obtained simultaneously, which further enables CNN-based iris segmentation to be applied in any regular iris recognition systems. By introducing an intermediate pictorial boundary representation, predictions of iris boundaries and segmentation mask have collectively formed a multi-label semantic segmentation problem, which could be well solved by a carefully adapted stacked hourglass network. Experimental results show that our method achieves competitive or state-of-the-art performance in both iris segmentation and localization on two challenging mobile iris databases.

Face Anti-Spoofing by Learning Polarization Cues in a Real-World Scenario
Face anti-spoofing is the key to preventing security breaches in biometric recognition applications. Existing software-based and hardwarebased face liveness detection methods are effective in constrained environments or designated datasets only. Deep learning method using RGB and infrared images demands a large amount of training data for new attacks. In this paper, we present a face anti-spoofing method in a realworld scenario by automatic learning the physical characteristics in polarization images of a real face compared to a deceptive attack.
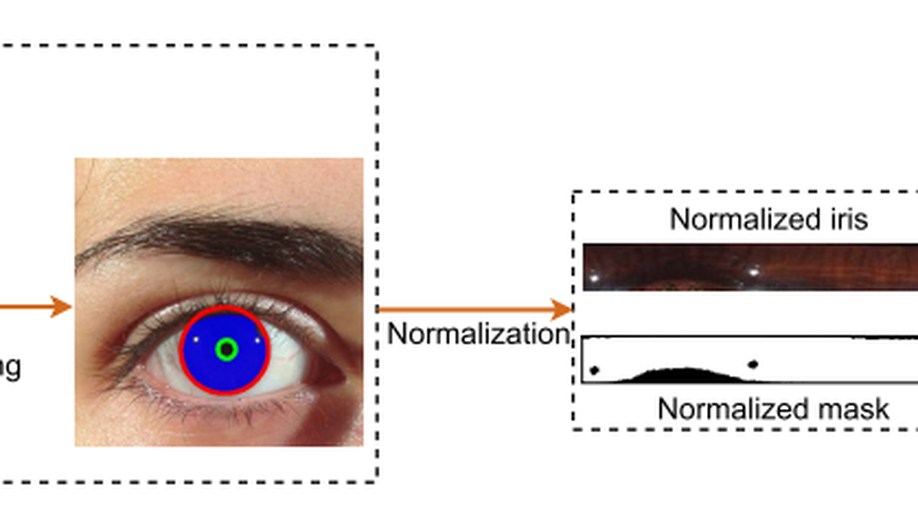
Towards Complete and Accurate Iris Segmentation Using Deep Multi-Task Attention Network for Non-Cooperative Iris Recognition
Iris images captured in non-cooperative environments often suffer from adverse noise, which challenges many existing iris segmentation methods. To address this problem, this paper proposes a high-efficiency deep learning based iris segmentation approach, named IrisParseNet. Different from many previous CNN-based iris segmentation methods, which only focus on predicting accurate iris masks by following popular semantic segmentation frameworks, the proposed approach is a complete iris segmentation solution, i.e., iris mask and parameterized inner and outer iris boundaries are jointly achieved by actively modeling them into a unified multi-task network. Moreover, an elaborately designed attention module is incorporated into it to improve the segmentation performance. To train and evaluate the proposed approach, we manually label three representative and challenging iris databases, i.e., CASIA.v4-distance, UBIRIS.v2, and MICHE-I, which involve multiple illumination (NIR, VIS) and imaging sensors (long-range and mobile iris cameras), along with various types of noises. Additionally, several unified evaluation protocols are built for fair comparisons. Extensive experiments are conducted on these newly annotated databases, and results show that the proposed approach achieves state-of-the-art performance on various benchmarks. Further, as a general drop-in replacement, the proposed iris segmentation method can be used for any iris recognition methodology, and would significantly improve the performance of non-cooperative iris recognition.
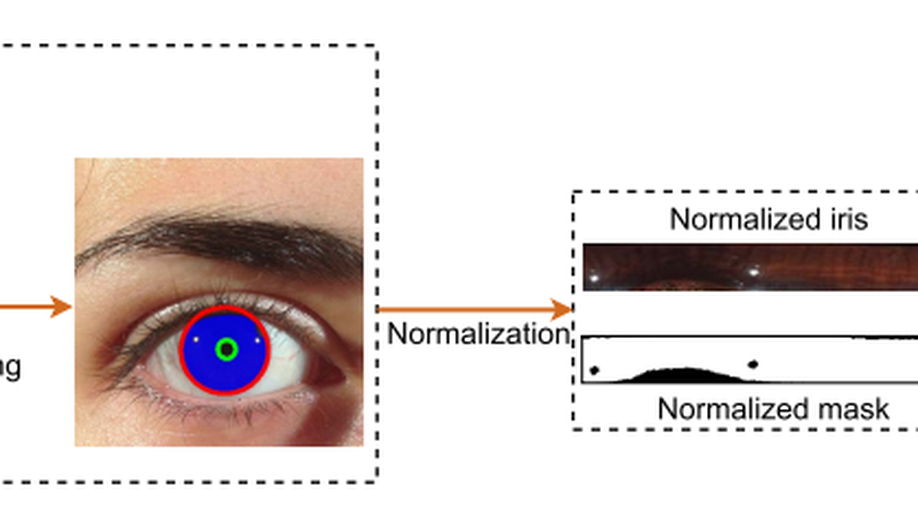
Towards Complete and Accurate Iris Segmentation Using Deep Multi-Task Attention Network for Non-Cooperative Iris Recognition
Iris images captured in non-cooperative environments often suffer from adverse noise, which challenges many existing iris segmentation methods. To address this problem, this paper proposes a high-efficiency deep learning based iris segmentation approach, named IrisParseNet. Different from many previous CNN-based iris segmentation methods, which only focus on predicting accurate iris masks by following popular semantic segmentation frameworks, the proposed approach is a complete iris segmentation solution, i.e., iris mask and parameterized inner and outer iris boundaries are jointly achieved by actively modeling them into a unified multi-task network. Moreover, an elaborately designed attention module is incorporated into it to improve the segmentation performance. To train and evaluate the proposed approach, we manually label three representative and challenging iris databases, i.e., CASIA.v4-distance, UBIRIS.v2, and MICHE-I, which involve multiple illumination (NIR, VIS) and imaging sensors (long-range and mobile iris cameras), along with various types of noises. Additionally, several unified evaluation protocols are built for fair comparisons. Extensive experiments are conducted on these newly annotated databases, and results show that the proposed approach achieves state-of-the-art performance on various benchmarks. Further, as a general drop-in replacement, the proposed iris segmentation method can be used for any iris recognition methodology, and would significantly improve the performance of non-cooperative iris recognition.
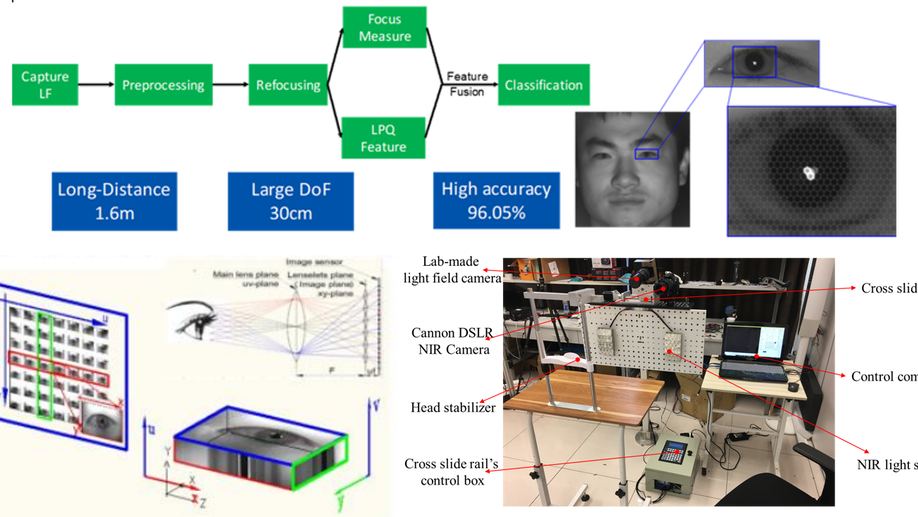
Iris Liveness Detection Based on Light Field Imaging
Light-field (LF) imaging is a new method to capture both intensity and direction information of visual objects, providing promising solutions to biometrics. Iris recognition is a reliable personal identification method, however it is also vulnerable to spoofing attacks, such as iris patterns printed on contact lens or paper. Therefore iris liveness detection is an important module in iris recognition systems. In this paper, an iris liveness detection approach is proposed to take full advantages of intrinsic characteristics in light-field iris imaging. LF iris images are captured by using lab-made LF cameras, based on which the geometric features as well as the texture features are extracted using the LF digital refocusing technology. These features are combined for genuine and fake iris image classification. Experiments were carried out based on the self-collected near-infrared LF iris database, and the average classification error rate (ACER) of the proposed method is 3.69%, which is 5.94% lower than the best state-of-the-art method. Experimental results indicate the proposed method is able to work effectively and accurately to prevent spoofing attacks such as printed and screen-displayed iris input attacks.
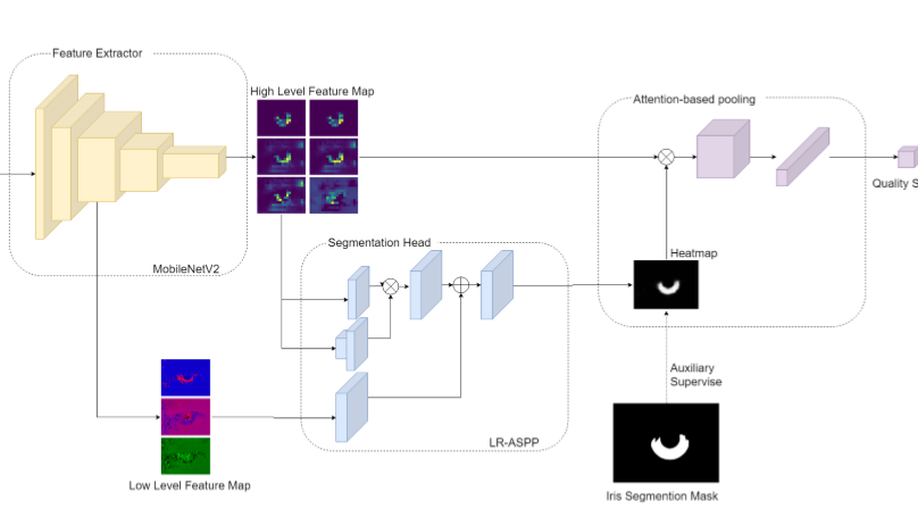
Recognition Oriented Iris Image Quality Assessment in the Feature Space
A large portion of iris images captured in real world scenarios are poor quality due to the uncontrolled environment and the non-cooperative subject. To ensure that the recognition algorithm is not affected by low-quality images, traditional hand-crafted factors based methods discard most images, which will cause system timeout and disrupt user experience. In this paper, we propose a recognition-oriented quality metric and assessment method for iris image to deal with the problem. The method regards the iris image embeddings Distance in Feature Space (DFS) as the quality metric and the prediction is based on deep neural networks with the attention mechanism. The quality metric proposed in this paper can significantly improve the performance of the recognition algorithm while reducing the number of images discarded for recognition, which is advantageous over hand-crafted factors based iris quality assessment methods. The relationship between Image Rejection Rate (IRR) and Equal Error Rate (EER) is proposed to evaluate the performance of the quality assessment algorithm under the same image quality distribution and the same recognition algorithm. Compared with hand-crafted factors based methods, the proposed method is a trial to bridge the gap between the image quality assessment and biometric recognition.
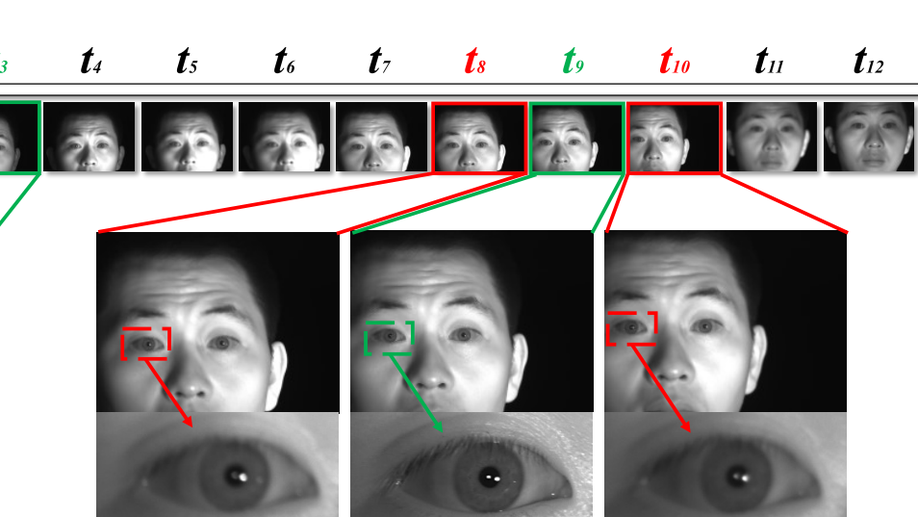
All-in-Focus Iris Camera With a Great Capture Volume
Imaging volume of an iris recognition system has been restricting the throughput and cooperation convenience in biometric applications. Numerous improvement trials are still impractical to supersede the dominant fixed-focus lens in stand-off iris recognition due to incremental performance increase and complicated optical design. In this study, we develop a novel all-in-focus iris imaging system using a focus-tunable lens and a 2D steering mirror to greatly extend capture volume by spatiotemporal multiplexing method. Our iris imaging depth of field extension system requires no mechanical motion and is capable to adjust the focal plane at extremely high speed. In addition, the motorized reflection mirror adaptively steers the light beam to extend the horizontal and vertical field of views in an active manner. The proposed all-in-focus iris camera increases the depth of field up to 3.9 m which is a factor of 37.5 compared with conventional long focal lens. We also experimentally demonstrate the capability of this 3D light beam steering imaging system in real-time multi-person iris refocusing using dynamic focal stacks and the potential of continuous iris recognition for moving participants.

ScleraSegNet: An Attention Assisted U-Net Model for Accurate Sclera Segmentation
Accurate sclera segmentation is critical for successful sclera recognition. However, studies on sclera segmentation algorithms are still limited in the literature. In this paper, we propose a novel sclera segmentation method based on the improved U-Net model, named as ScleraSegNet. We perform in-depth analysis regarding the structure of U-Net model, and propose to embed an attention module into the central bottleneck part between the contracting path and the expansive path of U-Net to strengthen the ability of learning discriminative representations. We compare different attention modules and find that channel-wise attention is the most effective in improving the performance of the segmentation network. Besides, we evaluate the effectiveness of data augmentation process in improving the generalization ability of the segmentation network. Experiment results show that the best performing configuration of the proposed method achieves state-of-the-art performance with F-measure values of 91.43%, 89.54% on UBIRIS.v2 and MICHE, respectively.
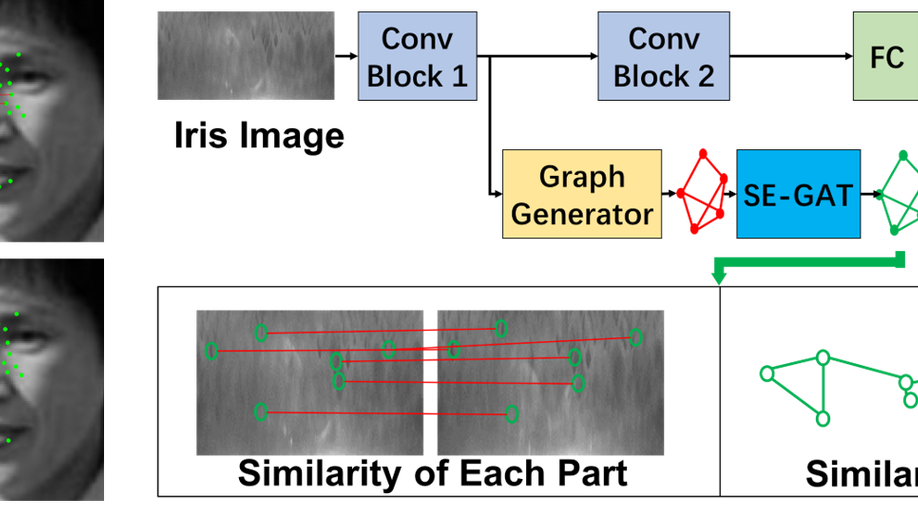
Dynamic Graph Representation for Occlusion Handling in Biometrics
The generalization ability of Convolutional neural networks (CNNs) for biometrics drops greatly due to the adverse effects of various occlusions. To this end, we propose a novel unified framework integrated the merits of both CNNs and graphical models to learn dynamic graph representations for occlusion problems in biometrics, called Dynamic Graph Representation (DGR). Convolutional features onto certain regions are re-crafted by a graph generator to establish the connections among the spatial parts of biometrics and build Feature Graphs based on these node representations. Each node of Feature Graphs corresponds to a specific part of the input image and the edges express the spatial relationships between parts. By analyzing the similarities between the nodes, the framework is able to adaptively remove the nodes representing the occluded parts. During dynamic graph matching, we propose a novel strategy to measure the distances of both nodes and adjacent matrixes. In this way, the proposed method is more convincing than CNNs-based methods because the dynamic graph method implies a more illustrative and reasonable inference of the biometrics decision. Experiments conducted on iris and face demonstrate the superiority of the proposed framework, which boosts the accuracy of occluded biometrics recognition by a large margin comparing with baseline methods.
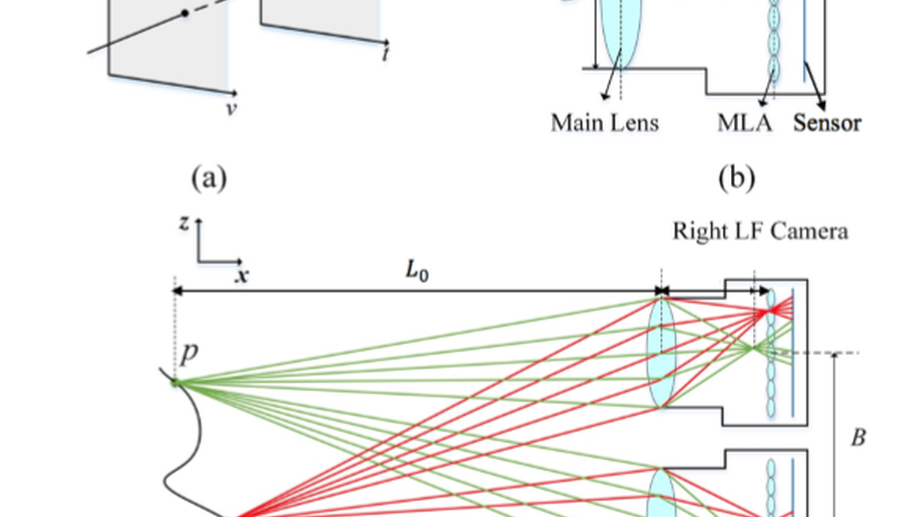
Binocular Light-Field: Imaging Theory and Occlusion-Robust Depth Perception Application
Binocular stereo vision (SV) has been widely used to reconstruct the depth information, but it is quite vulnerable to scenes with strong occlusions. As an emerging computational photography technology, light-field (LF) imaging brings about a novel solution to passive depth perception by recording multiple angular views in a single exposure. In this paper, we explore binocular SV and LF imaging to form the binocular-LF imaging system. An imaging theory is derived by modeling the imaging process and analyzing disparity properties based on the geometrical optics theory. Then an accurate occlusion-robust depth estimation algorithm is proposed by exploiting multibaseline stereo matching cues and defocus cues. The occlusions caused by binocular SV and LF imaging are detected and handled to eliminate the matching ambiguities and outliers. Finally, we develop a binocular-LF database and capture realworld scenes by our binocular-LF system to test the accuracy and robustness. The experimental results demonstrate that the proposed algorithm definitely recovers high quality depth maps with smooth surfaces and precise geometric shapes, which tackles the drawbacks of binocular SV and LF imaging simultaneously.
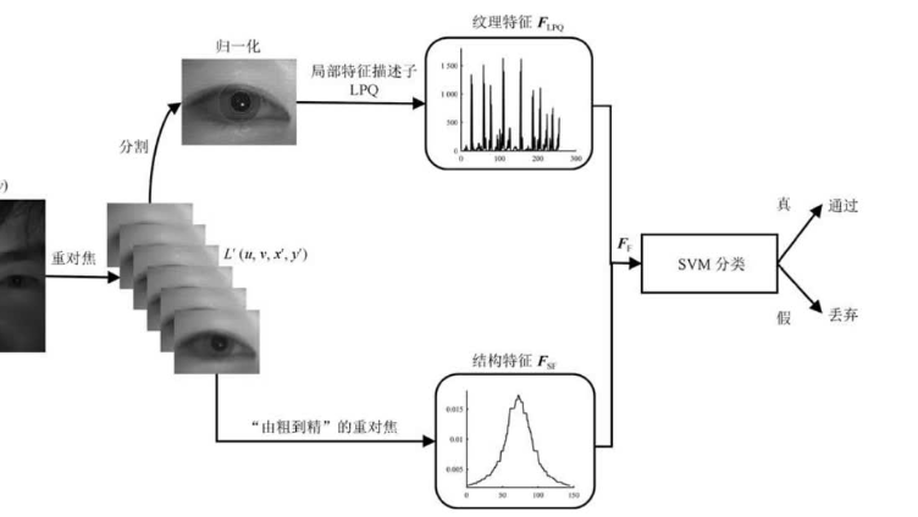
基于计算光场成像的虹膜活体检测方法
光场成像相对传统光学成像是一次重大技术革新,高维光场信息为生物特征识别的发展与创新带来了新机遇.虹膜身份识别技术以其唯一性、稳定性、高精度等优势广泛应用于国防、教育、金融等各个领域,但是现有的虹膜识别系统容易被人造假体虹膜样本欺骗导致误识别.因此,虹膜活体检测是当前虹膜识别研究亟待解决的关键问题.本文提出一种基于计算光场成像的虹膜活体检测方法,通过软硬件结合的方式,充分挖掘四维光场数据的信息.本方法使用实验室自主研发的光场相机采集光场虹膜图像,利用光场数字重对焦技术提取眼周区域的立体结构特征和虹膜图像的纹理特征,进行特征融合与虹膜分类.在自主采集的近红外光场虹膜活体检测数据库上进行实验,本方法的平均分类错误率(Average classification error rate,ACER)为3.69%,在现有最佳方法的基础上降低5.94%.实验结果表明本方法可以准确有效地检测并阻止打印虹膜和屏显虹膜对系统的攻击.
Seg-Edge Bilateral Constraint Network for Iris Segmentation
In this paper, we present an end-to-end model, namely Seg-Edge bilateral constraint network. The iris edge map generated from rich convolutional layers optimize the iris segmentation by aligning it with the iris boundary. The iris region produced by the coarse segmentation limits the scope. It makes the edge filtering pay more attention to the interesting target. We compress the model while keeping the performance levels almost intact and even better by using l1-norm. The proposed model advances the state-of-the-art iris segmentation accuracies.
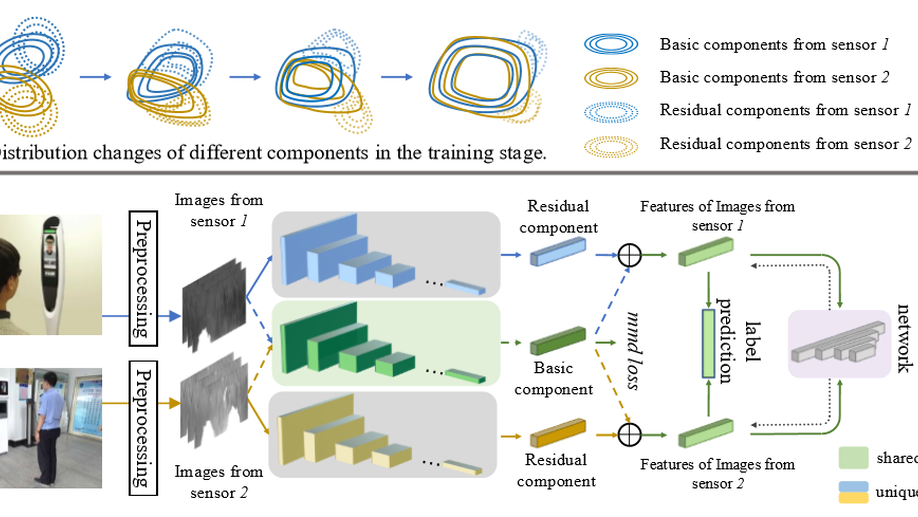
Cross-sensor iris recognition using adversarial strategy and sensor-specific information
Due to the growing demand of iris biometrics, lots of new sensors are being developed for high-quality image acquisition. However, upgrading the sensor and re-enrolling for users is expensive and time-consuming. This leads to a dilemma where enrolling on one type of sensor but recognizing on the others. For this cross-sensor matching, the large gap between distributions of enrolling and recognizing images usually results in degradation in recognition performance. To alleviate this degradation, we propose Cross-sensor iris network (CSIN) by applying the adversarial strategy and weakening interference of sensor-specific information. Specifically, there are three valuable efforts towards learning discriminative iris features. Firstly, the proposed CSIN adds extra feature extractors to generate residual components containing sensor-specific information and then utilizes these components to narrow the distribution gap. Secondly, an adversarial strategy is borrowed from Generative Adversarial Networks to align feature distributions and further reduce the discrepancy of images caused by sensors. Finally, we extend triplet loss and propose instance-anchor loss to pull the instances of the same class together and push away from others. It is worth mentioning that the proposed method doesn’t need pair-same data or triplet, which reduced the cost of data preparation. Experiments on two real-world datasets validate the effectiveness of the proposed method in cross-sensor iris recognition.
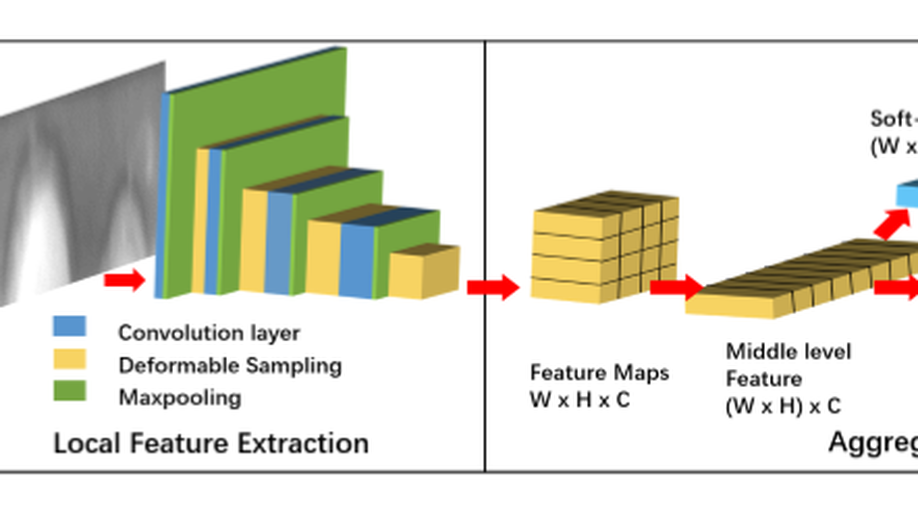
Alignment Free and Distortion Robust Iris Recognition
Iris recognition is a reliable personal identification method but there is still much room to improve its accuracy especially in less-constrained situations. For example, free movement of head pose may cause large rotation difference between iris images. And illumination variations may cause irregular distortion of iris texture. To match intra-class iris images with head rotation robustly, the existing soadminlutions usually need a precise alignment operation by exhaustive search within a determined range in iris image preprosessing or brute-force searching the minimum Hamming distance in iris feature matching. In the wild enviroments, iris rotation is of much greater uncertainty than that in constrained situations and exhaustive search within a determined range is impracticable. This paper presents a unified feature-level solution to both alignment free and distortion robust iris recognition in the wild. A new deep learning based method named Alignment Free Iris Network (AFINet) is proposed, which utilizes a trainable VLAD (Vector of Locally Aggregated Descriptors) encoder called NetVLAD [18] to decouple the correlations between local representations and their spatial positions. And deformable convolution [5] is leveraged to overcome iris texture distortion by dense adaptive sampling. The results of extensive experiments on three public iris image databases and the simulated degradation databases show that AFINet significantly outperforms state-of-art iris recognition methods.
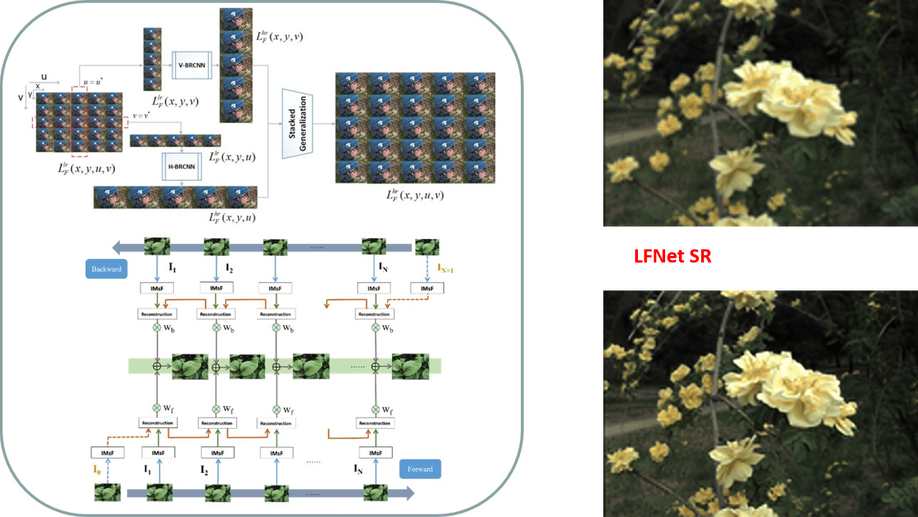
LFNet: A Novel Bidirectional Recurrent Convolutional Neural Network for Light-Field Image Super-Resolution
The low spatial resolution of light-field image poses significant difficulties in exploiting its advantage. To mitigate the dependency of accurate depth or disparity information as priors for light-field image super-resolution, we propose an implicitly multi-scale fusion scheme to accumulate contextual information from multiple scales for super-resolution reconstruction. The implicitly multi-scale fusion scheme is then incorporated into bidirectional recurrent convolutional neural network, which aims to iteratively model spatial relations between horizontally or vertically adjacent sub-aperture images of light-field data. Within the network, the recurrent convolutions are modified to be more effective and flexible in modeling the spatial correlations between neighboring views. A horizontal sub-network and a vertical sub-network of the same network structure are ensembled for final outputs via stacked generalization. Experimental results on synthetic and real-world data sets demonstrate that the proposed method outperforms other state-of-the-art methods by a large margin in peak signal-to-noise ratio and gray-scale structural similarity indexes, which also achieves superior quality for human visual systems. Furthermore, the proposed method can enhance the performance of light field applications such as depth estimation.
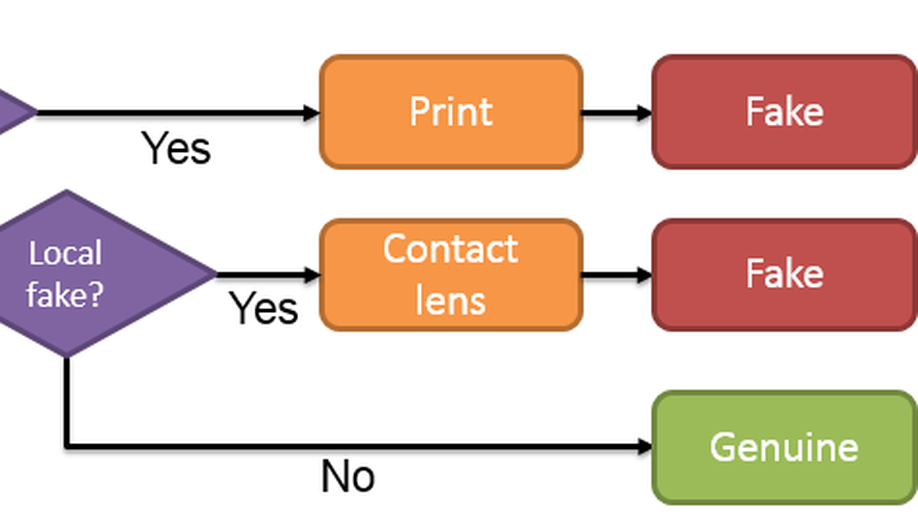
Hierarchical Multi-class Iris Classification for Liveness Detection
In modern society, iris recognition has become increasingly popular. The security risk of iris recognition is increasing rapidly because of the attack by various patterns of fake iris. A German hacker organization called Chaos Computer Club cracked the iris recognition system of Samsung Galaxy S8 recently. In view of these risks, iris liveness detection has shown its significant importance to iris recognition systems. The state-of-the-art algorithms mainly rely on hand-crafted texture features which can only identify fake iris images with single pattern. In this paper, we proposed a Hierarchical Multiclass Iris Classification (HMC) for liveness detection based on CNN. HMC mainly focuses on iris liveness detection of multipattern fake iris. The proposed method learns the features of different fake iris patterns by CNN and classifies the genuine or fake iris images by hierarchical multi-class classification. This classification takes various characteristics of different fake iris patterns into account. All kinds of fake iris patterns are divided into two categories by their fake areas. The process is designed as two steps to identify two categories of fake iris images respectively. Experimental results demonstrate an extremely higher accuracy of iris liveness detection than other state-of-the-art algorithms. The proposed HMC remarkably achieves the best results with nearly 100% accuracy on NDContact, CASIA-Iris-Interval, CASIA-Iris-Syn and LivDetIris-2017-Warsaw datasets. The method also achieves the best results with 100% accuracy on a hybrid dataset which consists of ND-Contact and LivDet-Iris-2017-Warsaw dataset
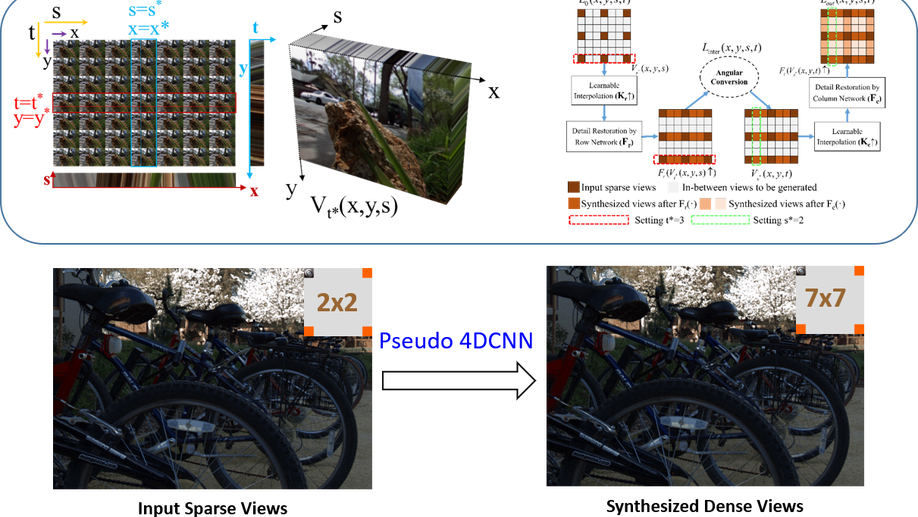
End-to-End View Synthesis for Light Field Imaging with Pseudo 4DCNN
Limited angular resolution has become the main bottleneck of microlens-based plenoptic cameras towards practical vision applications. Existing view synthesis methods mainly break the task into two steps, i.e. depth estimating and view warping, which are usually inefficient and produce artifacts over depth ambiguities. In this paper, an end-to-end deep learning framework is proposed to solve these problems by exploring Pseudo 4DCNN. Specifically, 2D strided convolutions operated on stacked EPIs and detail-restoration 3D CNNs connected with angular conversion are assembled to build the Pseudo 4DCNN. The key advantage is to efficiently synthesize dense 4D light fields from a sparse set of input views. The learning framework is well formulated as an entirely trainable problem, and all the weights can be recursively updated with standard backpropagation. The proposed framework is compared with state-of-the-art approaches on both genuine and synthetic light field databases, which achieves significant improvements of both image quality (+2 dB higher) and computational efficiency (over 10X faster). Furthermore, the proposed framework shows good performances in real-world applications such as biometrics and depth estimation.
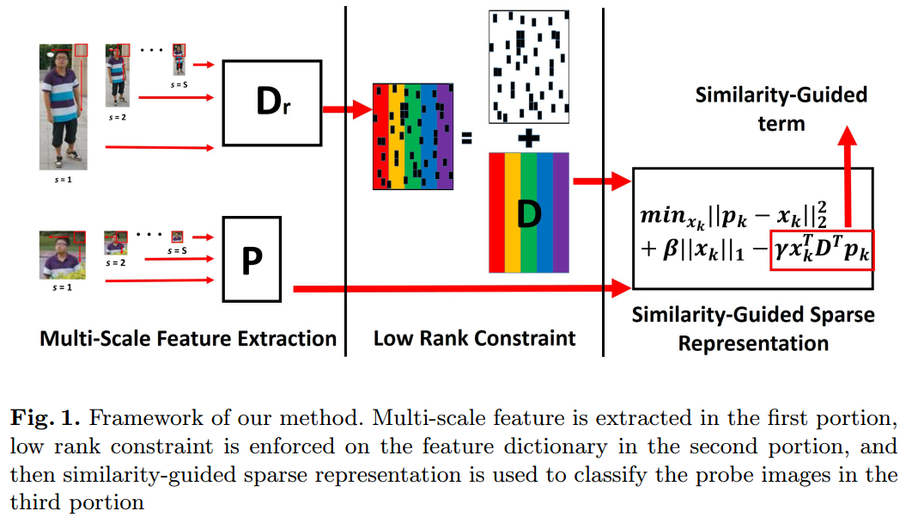
Robust Partial Person Re-Identification Based on Similarity-Guided Sparse Representation
In this paper, we study the problem of partial person reidentification (re-id). This problem is more difficult than general person re-identification because the body in probe image is not full. We propose a novel method, similarity-guided sparse representation (SG-SR), as a robust solution to improve the discrimination of the sparse coding. There are three main components in our method. In order to include multi-scale information, a dictionary consisting of features extracted from multiscale patches is established in the first stage. A low rank constraint is then enforced on the dictionary based on the observation that its subspaces of each class should have low dimensions. After that, a classification model is built based on a novel similarity-guided sparse representation which can choose vectors that are more similar to the probe feature vector. The results show that our method outperforms existing partial person re-identification methods significantly and achieves state-of-theart accuracy.

4D light-field sensing system for people counting
Counting the number of people is still an important task in social security applications, and a few methods based on video surveillance have been proposed in recent years. In this paper, we design a novel optical sensing system to directly acquire the depth map of the scene from one light-field camera. The light-field sensing system can count the number of people crossing the passageway, and record the direction and intensity of rays at a snapshot without any assistant light devices. Depth maps are extracted from the raw light-ray sensing data. Our smart sensing system is equipped with a passive imaging sensor, which is able to naturally discern the depth difference between the head and shoulders for each person. Then a human model is built. Through detecting the human model from light-field images, the number of people passing the scene can be counted rapidly. We verify the feasibility of the sensing system as well as the accuracy by capturing real-world scenes passing single and multiple people under natural illumination.
基于物联网的温室智能监控系统设计
根据现代温室监控与管理需求,基于物联网技术框架,设计并实现了一种基于物联网的温室智能监控系统。系统由现场监控子系统、远程监控子系统和数据库3部分组成。采用基于分布式CAN总线的硬件系统实现环境数据的实时采集与设备控制,将分布图法应用于采集系统离异数据的在线检测。为了提高远程监控子系统的响应速度与交互性,采用了基于异步JavaScript和XML技术(Ajax)的Web数据交互方式。结合温室环境调控的特点,将基于混杂自动机模型的温室温度系统智能控制算法应用于实际系统,实现了温室环境的自动调控。为保证设备控制的安全性,采用轮询法实现了现场监控子系统和远程监控子系统中设备状态的同步,并将基于Zernike矩的图像识别技术应用于双向型设备的状态检测,实现设备的自动校准。试验表明系统数据传输稳定,环境调控可靠,满足现代温室智能监控的需求。